[BigQuery]How does BigQuery work
in Google Cloud Platform on BigQuery, Work
BigQuery is two services in one
- Fast SQL Engine
- Managed storage for datasets
- serverless service
- fully managed
How does BigQuery work?
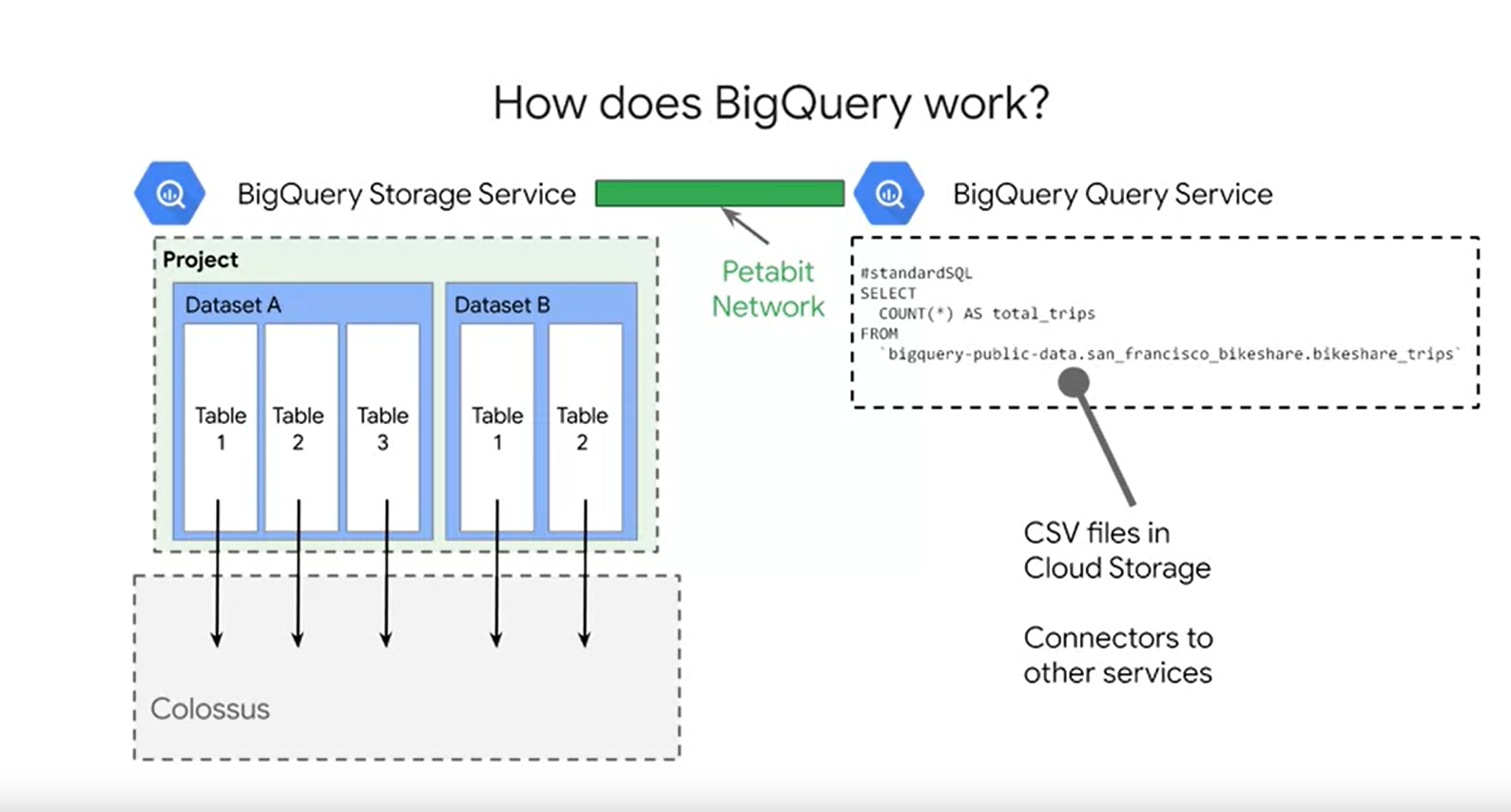
- user는 BigQuery가 어덯게 data를 disk에 저장하는지 걱정 할 필요 없음
large queries들에 대해 어떻게 machine들을 autoscale하는지 걱정 할 필요 없음
- data 관리는 project > dataset > table로 관리
- table들은
highly-compressed columns으로 저장 - Goole의 내부적인 file-system인
Colossus는 아래 2가지 특성을 제공- durablity
- global availability
- 모든 data는 project team에 의해서만 접근 가능
- storage서비스는
bulk data ingestion그리고streaming data ingestion을 제공 - Query서비스 아래 방법을 제공
- interactive(상호작용) 작동(Console,bq cli)
- batch queries(Console,bq cli)
- REST API - 7 languaged supported
- BigQuery Connector를 제공하여 BigQUery와 아래 GCP 데이터 처리 서비스간 복잡한 workflow를 간단하게 해줌
- DataProc
- Cloud Dataflow
Storage서비스와Query서비스는 내부적으로 쿼리를 생성하고 terabytes, petabytes의 데이터를 효율적으로 처리하도록 작동
BigQuery Manged Storage
- dataset의 metadata와 storage를 BigQuery는 관리
- 다양한 다른 format들로부터 dataset을 ingest 가능
- BigQuery native storage 내부에서는, data들은 Google BigQuery Team에 의해 관리
- automatically replicated
- autoscale for your query needs
- Querying external source directly(bypass BigQuery’s managed storage)
- 일반적으로 사용 사례는 다른팀이 유지관리하고 지속적으로 업데이트하는 상품의 가격표와 같이 상대적으로 작지만 지속적으로 변경되는 외부데이터소스 를 사용
- 보통 사용하지 않은 이유?
- data consistency(데이터 일관성)가 보장되지 않음
- 외부 data source가 진행중에 update가 되는 경우 BigQuery가 보장하지 않음
- 이에대해서는 Cloud Dataflow를 사용하여 BigQuery에 streaming data pipeline을 구축하는 것이 좋음
