Calling a private Google Cloud Function from on-prem
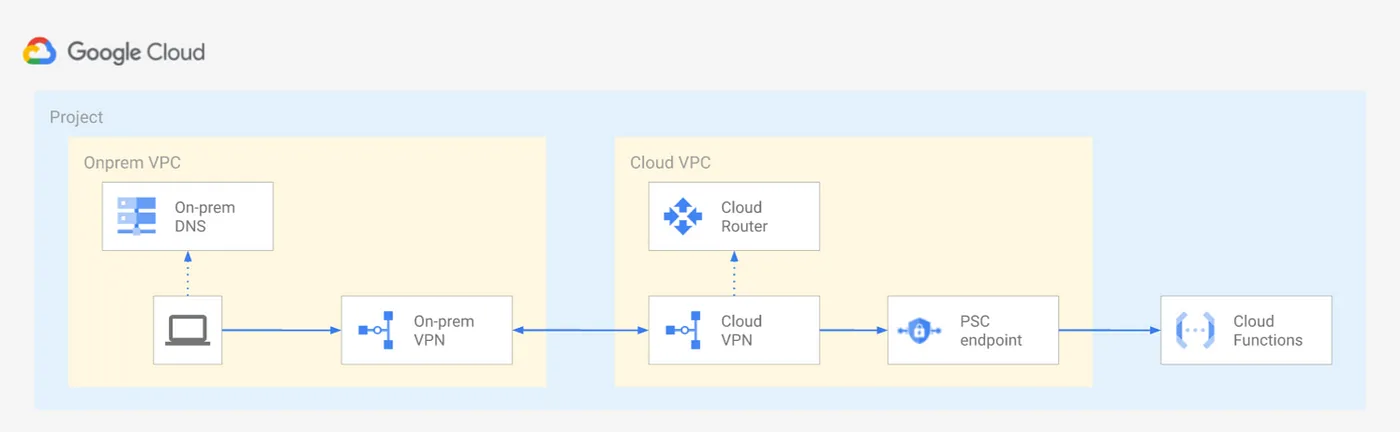
- 요건 :
- 많은 enterprise고객들이 Google Professional Service에게 어떻게 on-prem 서버에서 비공개적인 방법으로 (인터넷에 노출시키지 않고) Cloud Function을 호출하는지 문의
- 보안상 이유로 그들은 Cloud Function의 endpoint를 Public 인터넷에 노출을 꺼림
- 고객의 on-prem의 망과 GCP Private network에서 네트워크 트래픽이 흐르도록 원함
- 개요 :
- 새로운 Cloud Function을 생성 시 ingress setting을
allow internfal traffic으로 설정 가능하지만, documnet를 자세히 읽으면 Only requests from VPC network in the same project or VPC Service Controls Perimeter are allowed. All other request are denied with 403 error라고 적혀있음- 이 의미는 deploye되는 같은 프로젝트가 아닌 이상 function 호출이 불가능
Continue reading
Chatper 6. Architecture of BigQuery
Continue reading
Database - 4UUID (Primary key)
Continue reading
Database - OGG(Orgalce Golden Gate)
Continue reading
DataEngineering
MLOps
MLOps란 무엇인가?
- MLOps는 머신러닝작업(Machine Learning Operations)을 뜻함
- MLOps는 머신러닝모델을 Production으로 전환하는 프로세스를 간소화하고, 뒤이어 이를 유지관리하고 모니터링하는데 주안점을 둔 머신 러닝 엔지니어링의 핵심 기능
- MLOps는 협업 기능이며, 주로 DS,DevOps 엔지니어,IT로 구성
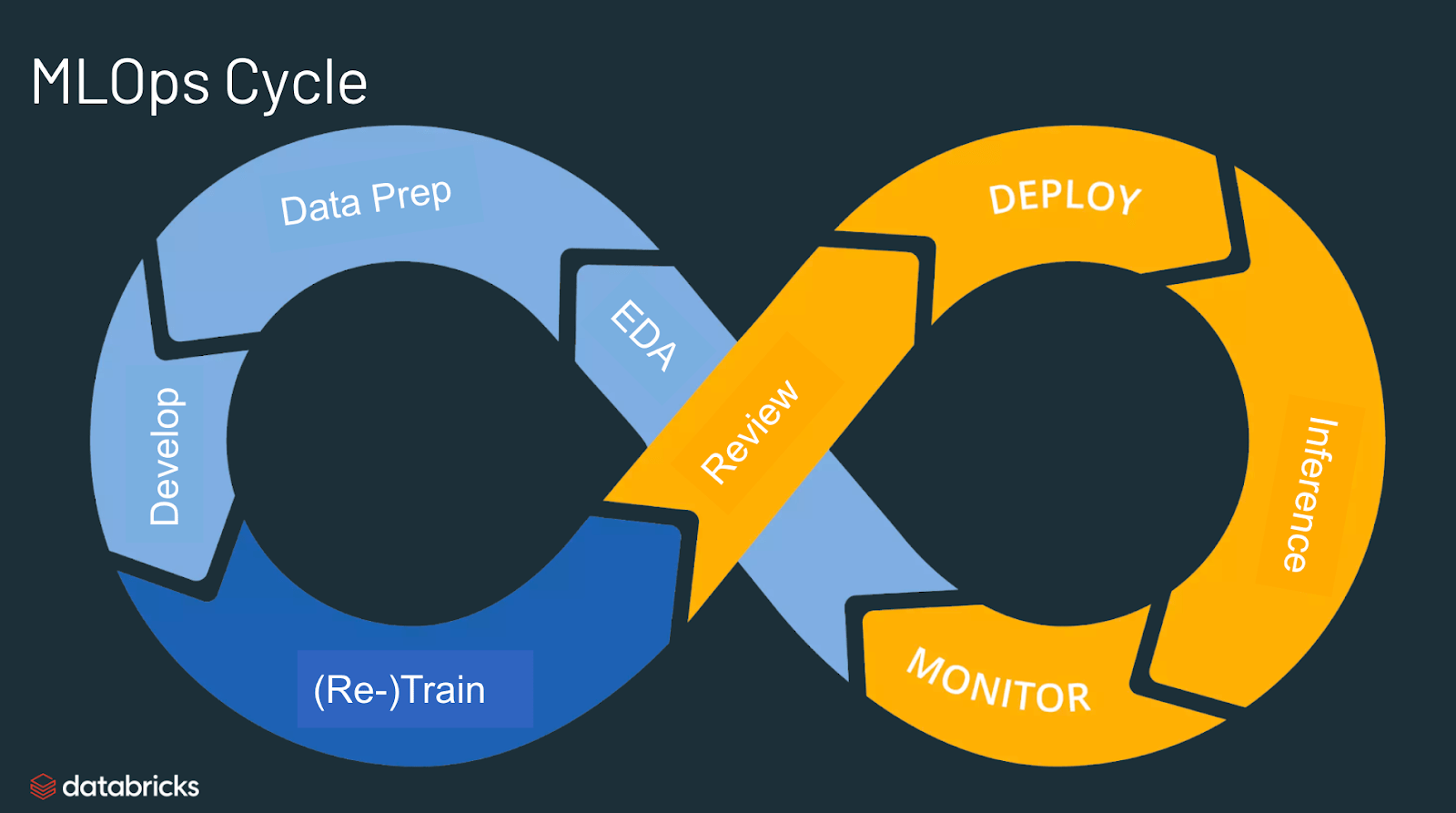
MLOps의 용도는 무엇인가?
- MLOps는 머신러닝왁 AI솔루션 제작과 품질에대한 유용한 접근법
- DS의 ML엔지니어는 MLOps 방식을 채택하여 협업을 추진하고 모델 개발과 Production 배포 속도를 증가
- 이를 위해 ML모델의 적절한 모니터링과, 검증과 거버넌스를 포함해 지속적인 CI/CD관례를 구현
MLOps가 필요한 이유는?
- 머신러닝의 생산은 쉽지 않은일
- 머신러닝의 수명 주기는 데이터수집, 데이터 준비, 모델 훈련, 모델 조정, 모델 배포, 모델 모니터링, 설명 가능성과 같은 복잡한 구성요소가 많이 모인 형태로 구성
- DE부터 DS, ML엔지니어링에 이르기까지 여러팀에 협업과 전달이 필요
- 따라서 이 모든 프로세르르 동기화하고 협력이 이루어지는 상태를 유지하려면 극히 엄격한 운영 원칙을 적용 필요
- MLOps는 머신러닝 수명 주기의 실험, 반복과 지속적 개선을 총 망라
MLOps의 장점?
- MLOPs의 주된 장점은
효율성, 확장성과 리스크 완화 - 사용 시 DS가 모델을 더 빨리 배포하고 양질의 ML모델을 제공하며 배포와 Production 속도를 높일 수 있음
- 확장성
- 관리를 지원하므로 수천개의 모델을 감독, 제어 ,관리, 모니터링하여 지속해서 통합,제공하고 지속해서 배포 가능
- 구체적으로, MLOps는 ML파이프라인 재현성을 제공하므로 여러 데이터 팀에서 좀더 긴밀하게 결합된 협업을 추진할 수 잇고 DevOPS팀과 IT팀의 갈등이 줄어들며 release 속도 빨라짐
- 리스트 완화
- 머신러닝 모델에는 철저한 규제 검토와 drift검사가 필요
MLOps의 구성요소
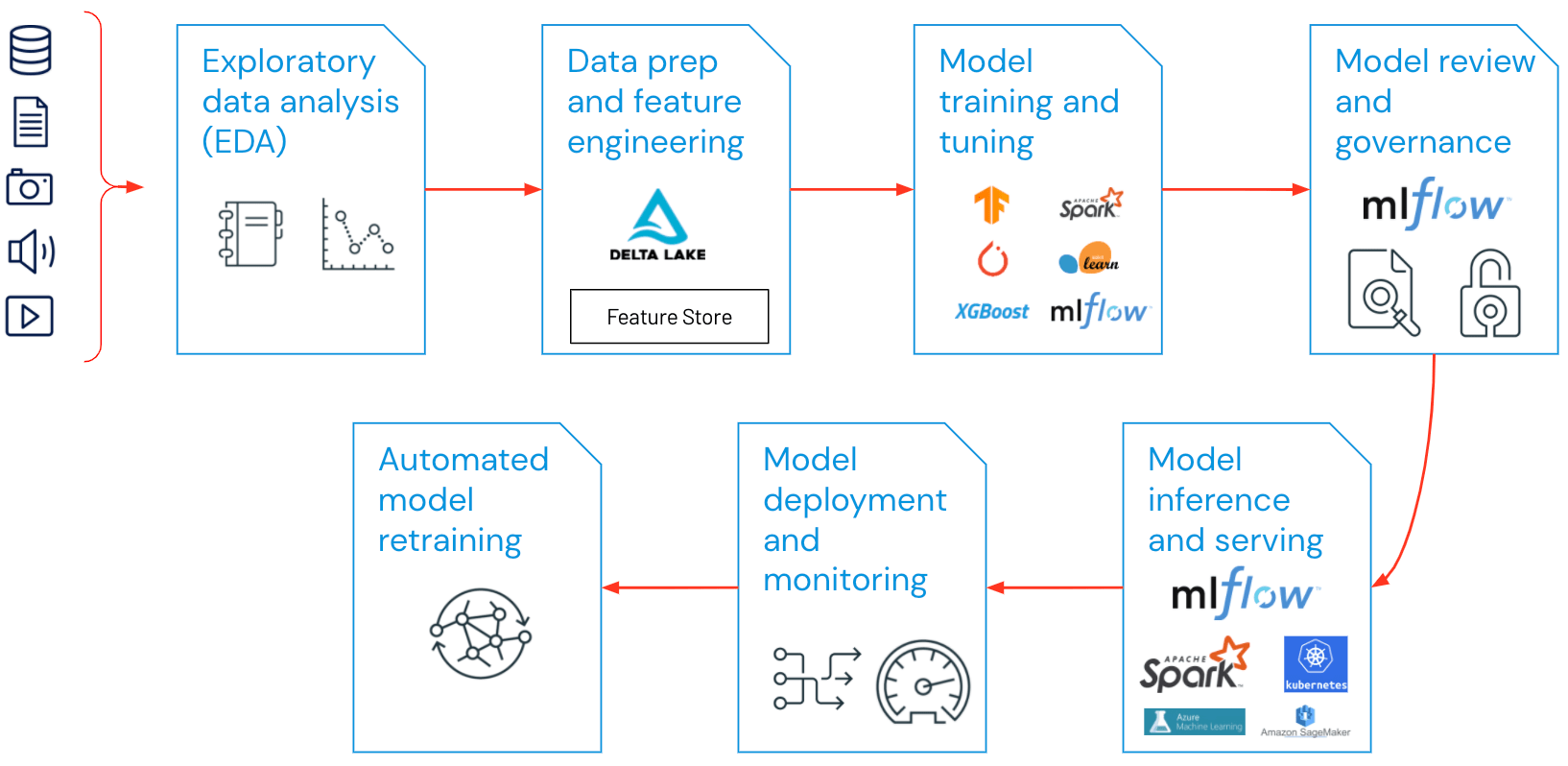
- 대부분 기업체에서 MLOps원칙을 활용하는 분야는 다음과 같음
- EDA(Exploratory Data Analysis,탐색적 데이터 분석)
- 데이터 준비와 피처 엔지니어링
- 모델 훈련 및 조정
- 모델 검토와 거버넌스
- 모델 유추와 서빙
- 모델 모니터링
- 자동 모델 재훈련
MLOps의 모범사례
- EDA(Exploratory Data Analysis)
- 재생산 가능하고 편집 가능하며 공유할 수 있는 데이터 세트, 표와 시각화를 만들어 머신 러닝 수명 주기에 적합한 데이터를 반복적으로 탐색, 공유하고 준비합니다.
- 데이터 준비와 피처 엔지니어링
- 데이터를 반복적으로 변환, 집계 및 중복 제거하여 미세하게 조정된 특징(feature)을 만듭니다. 이보다 더 중요한 것은 피처 스토어를 활용하여 여러 데이터 팀을 상대로 데이터를 표시하고 공유할 수 있게 하는 것입니다.
- 모델 훈련 및 조정
- scikit-learn이나 hyperopt와 같은 대중적인 오픈 소스 라이브러리를 이용하여 모델을 훈련하고 모델 성능을 개선할 수 있습니다. 이보다 더 간단한 대안으로는 AutoML과 같은 자동 머신 러닝 툴을 사용하여 시험 작동을 자동으로 수행하고, 검토와 배포가 가능한 코드를 만드는 방법도 있습니다.
- 모델 검토 및 거버넌스 - 모델 계보, 모델 버전을 추적하고 모델 아티팩트와 전환을 수명 주기 전체에 걸쳐 관리합니다. MLflow와 같은 오픈 소스 MLOps 플랫폼의 도움을 받아 ML 모델 전반에 걸쳐 검색, 공유와 협업을 수행합니다.
- 모델 유추와 서빙
- 모델 새로 고침 빈도, 추론 요청 횟수와 테스트 및 QA 면에서 이와 비슷한 프로덕션 세부 사항을 관리합니다. 리포지토리나 오케스트레이터(DevOps 원칙을 차용함)와 같은 CI/CD 툴을 사용하여 프로덕션 이전의 파이프라인을 자동화합니다.
- 모델 배포와 모니터링
- 권한 부여와 클러스터 생성을 자동화하여 등록된 모델을 (대량) 생산합니다. 또한 REST API 모델 엔드포인트를 활성화합니다.
- 자동 모델 재훈련
- 알림과 자동화를 생성하여 훈련과 추론 데이터가 서로 달라 모델 드리프트가 발생하는 경우 시정 조치를 합니다.
MLOps과 DevOPS는 무엇이 다른가?
- MLOps 플랫폼은 데이터 사이언티스트와 소프트웨어 엔지니어에게 협업 환경을 제공하여 반복 데이터 탐색, 실시간 공동 작업 기능을 지원하여 실험 추적, 피처 엔지니어링, 모델 관리 등을 간편하게 수행할 수 있게 해줍니다. 이뿐만 아니라 관리형 모델 전환, 배포와 모니터링까지 가능합니다. MLOps는 머신 러닝 수명 주기의 운영과 동기화 측면을 자동화해줍니다.
참고
- [databricks]https://databricks.com/kr/glossary/mlops)
Continue reading
DataEngineering
DataOps
DataOps 무엇인가?
- DataOps(데이터운영)는 DevOps팀과 데이터 엔지니어 및 데이터 과학 역할을 결합하여 데이터 중심 엔터프라이즈를 지원하는 도구, 프로세스 및 조직구조를 제공하는 신흥 분야
- DevOps에서 얻은 교휸을 데이터 관리 및 분석에 적용
- DataOps를 효과적으로 배포하면 분석 솔루션 시장 출시 시간을 단축하고, 데이터 품질 및 준수를 개선하며 데이터 관리비용이 절감되는 것으로 나타남
- 데이터운영은 제품이나 서비스 또는 솔루션이 아니라 방법론 (협업과 자동화를 통해 조직의 데이터 활용을 개선하려는 기술적이자 문화적인 변화)
DataOps 필요성
- 분석에 필요한 데이터 소스와 종류의 수, 복잡성이 높아지고 있습니다.
- 기업 내/외부에 분산되어 있는 데이터 소스에 엑세스하기 위해서는 많은 시간과 리소스를 투입해야 하고, 이를 지원하기 위한 새로운 스킬과 도구들이 필요
- DataOps는 데이터 관리자와 소비자 간의 데이터 흐름을 통합하고 자동화하여 데이터 활용을 개선 및 지원하는 역할을 하며, 데이터 거버넌스 하에서 필요한 곳 어디에서나 데이터를 제공할 수 있고, 누구나 쉽게 엑세스 할 수 있도록 속도와 품질을 높일 수 있음
DataOps 프레임워크란
- 기술에서 완전한 문화 변화에 이르는 5가지 필수 요소를 결합
- DataOps를 가능하게 하는 기술
- 주요기술, 서비스 및 프로세스의 지속적인 혁신을 지원하는 적응형 아키텍처
- 데이터를 보강하여 정확한 분석을 위한 유용한 컨텍스트 만드는것(지능형 메타 데이터)
- 기업의 데이터 관리 및 모델 관리방침에 따라 분석고 데이터 파이프라인을 구축하고 배포할 DataOps방법
- 문화와 사람
DataOps의 장점
데이터 보안 및 개인정보 보호, 데이터 사일로 문제, 분산된 데이터 증가에 따른 데이터 관리의 어려움을 극복하는 해결책으로 DataOps가 주목- 실시간 데이터 통찰력 제공
- 데이터 과학 애플리케이션의 주기시간을 단축
- 팀과 팀원간의 더 나은 커뮤니케이션 및 협업 가능
- 데이터 분석을 사용하여 가능한 모든 시나리오를 예측함으로써 투명성을 높임
- 프로세스는 재현 가능하도록 구축되록 가능할 떄마다 코드를 재사용
- 더 높은 데이터 품질을 제공
- 통합되고 상호 운용 가능한 데이터 허브를 만듬
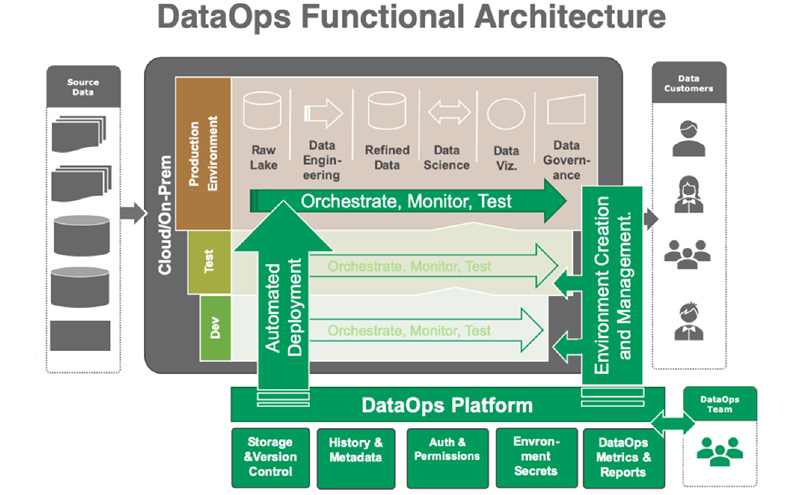
DataOps 프로세스
- Raw데이터를 정리하고 일반적으로 셀프 서비스 모델에서 쉽게 사용할 수 있도록 인프라를 개발
- 데이터를 엑세슷 할 수 있게되면 데이터를 조정하고 현재 시스템과 통합하는 SW,플랫폼 및 도구를 개발하거나 배포
DataOps 사례
- MAPR
- 비즈니스 결과를 개선하기위해 실시간 분석과 운영 애플리케이션을 결합하여 고객이 빅데이터 힘을 활용할 수 있는 컨버지드 데이터 플랫폼
- Quobole
- 방대한 양의 정형 및 비정형 데이터에서 가치를 추출하는 클라우드 기반 플랫폼
- John Snow Labs
- 데이터 통합, 코드없는 대화형 데이터 검색 및 분석, 협업 데이터 과학 노트북 환경, 대규모 API모델 생산을 특징 Enterprise platform
참고
Continue reading
DataEngineering
Data Mesh (기존 DW/DataLake 문제점)
- 데이터 기반의 서비스 활용이 중대되면서 데이터 메시에 대한 필요성이 요구
- DW나 DataLake에서 같이 통합된 데이터 관리 환경에서 조직의 사일로로로 인한 데이터 접근과 활용에서의 문제를 해결하는 방법으로 데이터 메시의 개념을 접근 가능
- Data Mesh란 기존에 DataLake나 DataWarehouse에서 중앙집중적으로 관리되었던 분석 데이터들을 탈중앙화하여 관리를 하는 개념
- 대부분 기업은 크게 Opertaion(운영)을 위한 데이터나 Analyze(분석)을 위한 데이터를 가지고 있다.
- Operational 데이터는 운영을 하면서 사용하거나 생성되는 데이터로서 현재상황에 대한 정보를 가지고 있고 Analytical 데이터는 통상적으로 여러 Operation데이터를 모아서 과거정보를 포함하는 사업의 전체적인 정보를 나타냄
- 예를 들어 전기회사에서 현재 정전상황을 나타내는 데이터는 Operational 데이터이고, 지역별 1년간의 정전 시간을 나타내는 데이터는 Analytical 데이터이다
Operational 데이터에서 Analytical 데이터로 변경을 할때 ETL(Extract, Transform, Load)를 해서 DW나 DataLake로 여러 Operational 데이터를 모으게 되는데, 이 부분에서 통상적으로 한계가 나타난다. 우선 새로운 Data Source가 발생하게 되면 기존 Data들과 같은 형태로 변경을 해야하지만 이는 기존 Table을 수정/새로운 Table을 생성하는 시간과 새로운 ETL을 생성하는 시간이 발생 한다.
만약 여러 종류의 Data Source들을 가지고 있고, 한팀에서 이 작업을 한다면 많은 가치가 발생하지는 않을 것 이다. 또한 주기적으로 새로운 종류의 Operational 데이터가 생성된다면, 이 작업은 아주 복잡한 작업이 될 것 이고, 결국 데이터양은 많으나 아무도 정확하게 어디서 무엇을 찾을 수 있는지 알 수 없게 된다. 이 상황에서 머신러닝과 같은 Data Science 작업과 권한 관리를 추가하게 된다면, 필요한 데이터가 어디있는지 찾아서 권한을 요청하고 정리하는 일이 Data Scientiest들이 많은 시간을 쓰는 일이 될 것이다 
Data Mesh는 이러한 문제를 해결하기 위해서 Data as a product 개념을 도입하여 탈중화를 이루고하는 개념 간단하게 정리하면 각 사업부별로 Analytic data를 제공하고 데이터 품질이나 응답시간에대한 SLA정하고 지키는 것. 예를들어서 위의 정전을 예제를 이용하면, 정전을 감지하는 팀에서 현재 정전상황(Operational 데이터) 뿐만 아니라 몇년치 정전 데이터(Analytical 뎅티ㅓ)를 전사적으로 약속한 방식(API, SQL 등등)을 제공하는 방식. 이 갠며은 결국 각 사업부별로 데이터 정제 및 데이터 서비스 제공을 위한 인프라 관리를 해야하는 결과를 초래하는데, 이는 중앙집중적으로 관리하던 데이터 엔지니어링 조직을 사업부별로 나누게 된다. 이는 중앙집중적으로 관리하던 데이터 엔지니어링 조직을 사업부별로 나누게 된다. 이렇게 각 사업부별로 Analytical 데이터를 제공하면 필요로 하는 조직에서 필요한 모든 데이터를 조회해서 필요한 Dashboard나 또다른 Analytical 데이터를 만들어서 제공하면 되는 것이다. 개념적으로 API를 이용하는 Microservice Architecture (MSA)와 유사한 점이 많다.
데이터 분석가와 도메인 기반 아키텍처
흔히 이러한 데이터 메시를 도메인 기반의 데이터 활용조직 또는 MSA기반의 데이터 아키텍처로 정리 실제 데이터 분석을 위해서는 데이터 분석 모형별 다양한 임시 데이터 처리 공간이 필요하고 또 실시간 변화되는 데이터를 추가해서 분석모델을 재학습하는 과정들이 지속적으로 동반
이러한 환경을 위해서는 분석 모델별 별도의 분석 환경과 분석 데이터가 개별로 관리되고 운영 되어야 한다 주로 Docker나 Kubernetes와 같은 가상 공간을 활용하여 분석에 필요한 자원을 할당하고 지속적인 학습과정들이 데이터 분석가를 통해 이루어 집니다.
이때 Data 분석가 또는 분석조직은 분석 모형 마다 별도로 각 업무 단위별로 자유로운 분석을 할 수 있는 데이터 처리구조가 요구 이러한 아키텍처를 도메인 기반의 데이터 아키텍처
데이터 파이프라인, 데이터 Mesh 그리고 데이터 서비스
데이터 분석의 목적은 고객에게 다양한 서비스로 제공하는 것으로 실시간 변화하는 데이터를 분석하여 데이터 서비스로 연결하는 과정까지 이어서 고려를 해야함. 이러한 환경을 데이터 Mesh라고 부름
데이터 분석 서비스가 이어지기 위해서는 실시간의 변화된 데이터를 끌어와서 분석모형을 재학습하고, 실시간의 서비스로 연결하는 데이터 파이프라인을 이용하는 전체 데이터 처리 과정에서 데이터 플랫폼의 개념을 찾을 수 있습니다.
Data Mesh는 ?
데이터 메시는 MSA마찬가지로 기존의 데이터 레이크에서 수집, 저장, 변환, 분석, 추론을 하는 모놀리식 방법과 다르게, 데이터 파이프라인을 활용하여 여러 도메인의 데이터를 쉽게 찾고 데이터 활용을 위한 접근 절차로 쉽게 정의하게 합니다.
참고



Continue reading
DataEngineering
Data Fabric
Data Fabric란?
- 하이브리드 멀티 클라우드 환경을 포괄하는 다양한 엔드포인트에서 일관된 기능을 제공하는 아키텍처 및 데이터 서비스 세트
- 클라우드, 온프레미스, 에지 장치 전반에서 데이터 관리 관행과 실무를 표준화하는 강력한 아키텍처
- 데이터 가시성 및 통찰력, 데이터 엑세스 및 제어, 데이터 보호와 보안을 제공
- Data Fabric이란 아키텍처, 데이터 관리 및 통합 SW, 공유 데이터로 구성된 종단 간 데이터 통합 및 관리 솔루션으로 조직의 데이터 관리 지원
- Data Fabric은 전 세계 조직의 모든 구성원들에게 실시간을 통합되디고 일관된 사용자 경험과 데이터 엑세스를 제공
- Data Fabric은 다양한 종류의 애플리케이션, 플랫폼 및 데이터를 저장하는 장소에 관계없이 조직을 도와 데이터를 관리하여 복잡한 데이터 문제와 사용사례를 해결할 수 있도록 설계
- 분산 데이터 환경에서 원활한 엑세스 및 데이터 공유가 가능해짐
- 원활한 데이터 엑세스 고유, 통합관리 기능
- Data Fabric은 사일로에 있는 데이터용으로 설계되어 스토리지 전반에 걸쳐 데이터를 원할하게 엑세스하고 통합할 수 있는 논리적 DW아키텍처 수단
Data Fabric 사용이유?
- 모든 데이터 중심 조직은 시간,공간 다양한 소프트웨어 유형 및 데이터 위치의 장애를 극복하는 전체적인 ㅈ버근 방식을 필요
- 데이터는 필요로 하는 사용자가 접속할 수 있어야 하며 방화벽 잠겨 이썩나 다양한 위치에 단편적으로 위치하지 않아야합니다.
- 일반적으로 다양한 소스에서 데이터를 수집하는 것이 문제가 되지는 않지만 많은 조직들은 다른 소스와 데이터를 통합, 처리, 선별 및 변환 가능
- 데이터 관리 프로세스의 이 중요한 부분은 고객, 파트너 및 제품에 대한 포괄적인 관점을 제공하기 위한 것
- 이를 통해 조직은 경쟁 우위를 확보하고 고객 요구를 더 잘 충족하고 시스템을 현대화하며 클라우드 컴퓨팅 파워를 활용 할 수 있습니다.
- Data Fabric은 조직의 사용자가 어디에 있든 전 세계 퍼져 있는 천으로 시각적으로 묘사할 수 있습니다.
- 사용자는 이 패브릭의 어느 위치에 있어도 제약 없이 실시간으로 다른 위치의 데이터에 계속 접속 할 수 있음
- 오늘날 데이터의 문제점
- 다중 온플레미스 및 클라우드 위치에 위치
- 정형 및 비정형 데이터
- 데이터 유형의 다양성
- 플랫폼 환경의 다양성
- 다양한 파일 시스템, 데이터베이스 및 SaaS 애플리케이션에서 유지 관리
Data Fabric 구현
- Data Fabric :OLTP(온라인 트랜잭션 처리)개념으로 시작
- OLTP에선는 모든 트랜잭션에 대한 세부 정보가 데이터베이스에 삽입, 업데이트 및 업로드
- 데이터는 구조화 되고 정리되며 추가 사용을 위해 중앙사일로 에 저장
- 패브릭은 어느 지점에서나 모든 데이터 사용자가 raw 데이터를 가져과 여러 결과를 도출할 수 있으므로 조직에서 데이터를 활용하여 데이터를 확장, 조정 및 개선 가능
- 데이터 패브릭을 성공적으로 구현하려면 다음 사항이 필요
- 애플리케이션 및 서비스
- 데이터 호기득에 필요한 인프라가 구축되는 곳. 여기에는 조직과 상호 작용 할 수 있는 앱 및 GUI개발이 포함
- 생태계 개발 및 통합
- 데이터를 수집, 관리, 저장하는데 필요한 생태계를 생성. 고객의 데이터는 데이터 손실을 방지하면서 데이터 관리자와 스토리지 시스템으로 전송
- 보안
- 모든 소스에서 수집한 데이터는 적절한 보안 기능으로 관리
- 스토리지 관리
- 데이터는 접속 가느하고 효율적인 방식으로 저장되며 필요할 때 확장할 수 있어야합니다.
- 전송
- 조직의 지리적 위치의 모든 지점에서 데이터에 접속하는 데 필요한 인프라를 구축
- 엔드포인트
- 스토리지 및 엑세스 포인트에서 소프트웨어 정의 인프라를 개발하여 실시간 통찰력 얻어야함
참고
Continue reading
Find it and do what you want
It’s safe to say that the find command in Linux is one of the must-know operations for backend developers, unless you are using a Windows-server
Continue reading
Modul1. CI/CD개요
Continue reading
Chatper 1. What is Google BigQuery
Continue reading
IT용어
CAPEX란
Capital Expenditure의 약자- 정의
- 미래의 이윤을 창출하기 위해 지출된 비용. 즉 돈을 벌기 위해 투자한 투자비용
- 자본적 지출
설비투자비용 - 자산이므로 자산계정에 추가
OPEX
Operating Expenditure의 약자- 정의
- 영업비용(운영 지출)
- CAPEX를 통해 취득한 자산을 유지/보수 하거나 운영하는데 들어가는 비용
- 판관비 등
TCA
Total Cost Acquisition- 초기 도입비용
Continue reading
Continue reading
Continue reading
Problem

Solution
- 주어진 문자열에서 반복하지않은 문자를 반환 없으면 -1을 리턴
Approach 1 : Naive
Intuition
- 주어진문자열의 {문자:개수}를 가지는 dictionary를 구현
- 주어진 문자열의 반복하여 개수가 1인 문자를 처음 발견 시 리턴
Algorithm
Initialize an empty answer list. Iterate on the numbers from 1 … N1…N. For every number, if it is divisible by both 3 and 5, add FizzBuzz to the answer list. Else, Check if the number is divisible by 3, add Fizz. Else, Check if the number is divisible by 5, add Buzz. Else, add the number.
Approach 2 : Hash it!
Intuition
This approach is an optimization over approach 2. When the number of mappings are limited, approach 2 looks good. But what if you face a tricky interviewer and he decides to add too many mappings?
Having a condition for every mapping is not feasible or may be we can say the code might get ugly and tough to maintain.
What if tomorrow we have to change a mapping or may be delete a mapping? Are we going to change the code every time we have a modification in the mappings?
We don’t have to. We can put all these mappings in a Hash Table.
Algorithm
Put all the mappings in a hash table. The hash table fizzBuzzHash would look something like { 3: ‘Fizz’, 5: ‘Buzz’ } Iterate on the numbers from 1 … N1…N. For every number, iterate over the fizzBuzzHash keys and check for divisibility. If the number is divisible by the key, concatenate the corresponding hash value to the answer string for current number. We do this for every entry in the hash table. Add the answer string to the answer list.


Code
Continue reading
