The Battle for Programming Language is Not Over Yet
기술이 빠르게 발전하고 많은 프레임워크가 등장함에따라 올바른 작업에 적절한 Programming Language를 선택하는 것은 어려울 수 있다
Python’s Regioon of Dominance
오늘날 데이터 엔지니어의 작업은 SQL database를 상호 작용하고 쿼리를 실행하는 것뿐만 아니라 아래와 같은 작업도 실행 시킬 수 있어야 한다
- Managing infrastructure(through infrastructure as a code with frameworks with Terraform/Pulumi)
- Developing data pipelines
- Developing microservices/API/data frameworks
- Interacting with cloud services SDKs
Python has massive adoption today, and here’s why:
- The learning curve for new programmer folks is pretty easy (notebook helps a lot)
- The data science ecosystem : machine leraning, visualization, deep learning
- Cloud adoption : all major cloud providers have a well-supported Python SDK
The Brighter Future and Rust’s Potential
- Golang seemed to be a good competitor. Terraform and Kubernetes have massive adoption, and both are written in Golang. It’s also be desgined and supported by a major cloud Provider : google
- That being said, there aren’t that many data frameworks built aroud Golang. The learning curve is also a siginificant barrierr to catch-up for Python’s data average users.
Who would be next candidate then? Rust Here are four non-exhausitive reasons.
- General popularity
- according to stack overflow study, Rust has benn most loved Programming language for four years in a Row
- Google trends also show a steady growth of Rust and
general fatigur for Python - Another big news is that
Rust will be second language of the official Linux Kernel
- Performance and low-memory footprint
- Rust’s performance is at another level because it’s compiled directly into machine code. No virtual machine, no interpreter sitting between your code and the computer
- In our cloud computing era, the footpring of your program on you compute system is driectly impacting your costs, but also the electrictiy usage and there the impact on the environment
- An interesting study by the New Stack revealed which programming language consumes the least electrictiy. Rust is at the top of that lists, while Python at the bottom
- Interoperability with Python
- What if you could rewrite some part of your existing Python code base and still use it through your main Python program? That’s combining the best of the two worlds.
- A concrete use case would be to perform specific actions against s3 files, which can be pretty slow in Python. With AWS annoucning recently their AWS SDK ins Rust in developer preview, this is something you could perform in Ruut. Using a Rust binding for a Python library like
PyO3 enables you to quickly do a simple interface to call your Rust program within Python
- A lot of data projects are being rebuilt in Rust
Apache Arrow is key common interface to build data processing frameworks. It has a great Rust implementation, and it’s pubshing other data projects to rise:
- Spark’s Rust equivalent called
data fusion Apache Delta Lake has a native Rust interface with binding in Python and Ruby- Confluent kafka offer now a Rust binding
Is is Worth it? Through?
Initially both Rust and python were built with differnet goals. The learning curve is steeper for Rust, and it will be difficult for some data citizens(Data scientists, data analysts) to jump on the boat. you are making a trade-off between performance and simplicity
The data enginner role evolves more strongly as devpos/backend engineer rather than just the SQL Person. t makes sense to try out Rust for some use cases in that context. Rust’s mindset is also valuable for any future programming language you would learn next.
In the very end, programming languages are just part of your toolbelt, and it doesn’t hurt to have more than one, especially when you see that the data engineer scope is expanding exponentially lately
참고
medium
Continue reading
Problem

Solution
- 주어진 문자열에서 반복하지않은 문자를 반환 없으면 -1을 리턴
- Sol1
- 주어진문자열의 {문자:개수}를 가지는 dictionary를 구현
- 주어진 문자열의 반복하여 개수가 1인 문자를 처음 발견 시 리턴
Code
Continue reading
Issue
dockerd : http : Accept error : accept unix /var/run/docker.sock : accepty4 : too many open files
Continue reading
Continue reading
AI CNN
입력 tensor의 공간정보를 무시하는 Flatten Later
- fnn(feedforward neural network)로 학습할떄는 입력데이터가 1차원의 벡터로 변환
- 그래서 이미지의 가로세로 공간적인 정보를 무시하고 무조건 납작하게 하는 Flatten 레이어를 사용
- 28X28의 흑백이미지는 flatten layer를 통과하면 784길이의 벡터가 된다
CNN(Convolutional Neural Network)
- 이미지 처리에 특환된 신경망
- Flatten layer를 사용하지 않고 이미지의 정보 그대로 활용
- 데이터 처리는 fnn에서와 마찬가지로 가중합을 한 뒤 비선형 함수(relu)활용

- 2가지 처리영역이 존재
- feature extraction 영역
- convolution과 pooling라는 2가지 연산을 통해 수행
- 이미지 형태로 그대로 네트워크가 받아 들임
- 그 위를 어떤 작은 네모 필터가 돌아다니면서 정보를 추출하여 다음으로 넘기고 추출된 정보(feature)중 핵심적인 것만을 남기고 불필요한 정보는 버리는 샘플링 작업이 있음
- 추출 및 샘플링 이 두 과정을 여러번 반복하다 보면 이미지에서 주요한 특징만 남음
- task 수행 영역
- 추출된 정보를 다시 1차원으로 누르고 Dense레이어 원하는 대로 연결 다음 softmax로 원하는 수만큼 분류를 한다든지 하는 역할을 수행
–
Convolution
- 이미지로부터 feature를 추출하는 연산
- conv필터가 입력 image를 상화좌우로 훑으며 주요한 특징이 있는지 찾아내는 과정
- conv 필터가 여러개 설정하면 그만큼 이미지로부터 다양한 특징을 추출 가능
- convolved feature라고 부름
- 이미지를 pixel단위 훑을때 겹쳐지는 pixel과 가중치를 곱해서 그 가중합의 결과를 다음을 ㅗ넘김
convolution연산이 이미지로부터 특징을 추출하는 역할- 입력 tesnor와 convolution필터가 가중합을 한 뒤 , relu와 같은 activation function을 취해주면 됩니다
Color image
- 컬러이미지는 3차원 텐서이므로 conv를 적용하기 위해 conv 필터 또한 3차원으로 생겨야함
- FNN에서 Dense layer에 노드를 여러 개 두어 서로 다른 가중합 및 feature 추출을 진행하듯이, CNN에서도 서로 다른 필터를 여러 개 두어 입력 이미지로부터 여러 feautre를 추출 가능
conv필터를 많이 두면 둘수록 더 다양한 feature를 꺼낼 수 있음
–
Pooling
- conv필터가 연산이 끝난 뒤, 결과로부터 정보를 추리하는 Pooling 연산이 이어짐
- pooling 진행하면 가로세로 차원크기가 축소되는 subsampling 효과
- pooling연산은
feature map(pooling 대상영역)을 역시 상하좌우를 훑으며 핵심적인 정보만을 영역별로 샘플링 - 주로 영역 내 가장 큰 값만을 나머지 값을 버리는 maxpooling 방식을 적용(강력한 특징만 남김)
- conv 연산이 추출한 feature 정보를 단순화하면서 차원을 줄이지만 공간위치정보는 그대로 유지한다는 특징
–
Summary
Feature Learning
- 이미지로부터 convolution연산을 통해 특징을 학습
- Activation function을 거쳐 non-linearity 적용
- Pooling으로 공간정보를 유지하면서도 차원을 축소
Task수행
- conv와 pooling으로 도출된 고차원의 feature를 분류를 하기 위해 납잡하게 1차원으로 펼침
- Class수만큼 분류되도록 Dense로 연결
- Class수만큼 probability로 표현
참고
Continue reading
AI Conecpt
시그모이드 뉴런(Sigmoid Neuron)
Deep Learning
Deep Neural Network
- sigmoid 뉴런과 같은 형태의 인공뉴런을 여러 층 연결하면 인공 신경망이 된다. 일반적으로
두 층 이상의 뉴런을 쌓게 되면 Deep하다고 말한다 - input layer : 데이터가 들어오는 layer
- output layer : 결과를 출력하는 마지막 layer
- hidden layer : 이 두 레이어 사이에 있는 레이어는 몇 개가 있든지간에 모두 hidden layer라고 부름
Deep learning 정의
- 기계학습 알고리즘의 종류
use a cascade of multiple layers of nonlinear processing units for feature extraction and transformation. each successvie layers uses the output from the previous layers as input- 특징을 추출하거나 변형하기 위해
비서현 처리유닛(시그모이드 뉴런)을 순차적으로 연결되는 여러 레이어를 사요. 각각의 이어지는 레이어는 이전 레이어의 출력을 입력으로 받아들임 learn multiple levels of representations that correspond to differenct levels of abstraction; the levels form a hierarchy of concepts- 다양한 레벨의 표현(feautre)을 학습하는데, 이 표현들은 서로 다른 추사황 레벨과 상응한다. 이는 레벨은 개념의 계층을 이룬다.
Multi Layrer Perceptron
- 여러층의 neuron들을 쌓아 구성한 신경망
- 각 layers는 모든 node끼리 서로 연결되어 weight를 가지는 것이 특징
- 가장 간단한 형태의 신경망으로, 학습 파라미터 수에 비해 성능이 높지는 않아 효율적이지는 않지만 간단한 실습에 사용
- Tensorflow Developer Certificate에서도 관련 문제가 나옴
Loss Function
loss function은 값을 예측하려할 때 데이터에대한 예측값과 실제의 값을 비교하는 함수로 모델을 훈련시킬 때 오류를 최소화 시키기 위해 사용되며, 주로 regression(회귀)에서 사용한다. 모델의 성능을 올리기 위해 loss함수를 임의적으로 변형 가능
Loss Function 종류
MSE(Mean_Squared_error)
- 예측한 값과 실제 값 사이의 평균 제곱 오차를 정의. 차가 커질수록 제곱 연산으로 인해서 값이 더욱 뚜렷해짐
RMSE(Root Mean Squared Error)
- MSE에 root를 씌운 것으로 MSE와 기본적으로 동일.
MSE값은 오류의 제곱을 구하기 떄문에 실제 오류 평균보다 더 커지는 특성이 있어 왜곡을 줄여준다
Binary Crossentropy
- 실제 label과 예측 label간의 교차 엔트로피 손실을 계산. label class(0,1)가 2개만 존재할때 사용
Categorical Crossentropy
- 다중 분류 손실함수로 출력값이 one-hot encoding된 결과로 나오고 실측 결과와의 비교시에도 실측 결과는 one-hot encoding형태로 구성된다.
- 출력 값이 one-hot encoding된 결과로 나온다. -> label(y)을 one-hot encoding해서 넣어줘야 함
- sample이 여러개의 class에 속함
Sparse_Categorical_Crossentropy
- 위와 같은 다중 분류 손실함수이지만, 샘플값은
정수형 자료이다- e.g. [0,1,2] -> Dense(3, activation=’softmax’)로 하고 출력값도 3개가 나오게 된다
- 즉 샘플 값을 입력하는 부분에서 별도 one-hot encoding하지 않고 정수값 그래도 줄 수 있다. compile단계에서 loss func만 바꿔주면 된다.
- integer type 클래스 -> one-hot encoding하지 않고 정수 형태로 label(y)을 넣어줌
- sample이 오직 하나의 class
Loss
- 학습할 대상인 weight와 bias등을 묶어서
parmeter라고 부름 - performance measure : 인공신경말 모델이 얼마나 좋은지를 평가 하는 기준. 모델이 예측한 예측값과 맞추어야하는 모범답안 y의 차이를 정량화해주는 함수
- 이러한 차이
d(y,y')를 우리가 가진 모든 데이터에 대해 구하여 더한 것을 Loss 또는 Cost라고 부름 - 둘다 모델이 정답을 얼마나 못맞췄느냐를 정량화해주는 값
학습의 목적은 d(y,y')가 차이를 나타내는 0이상의 값이라면 학습의 목적은 L(w,b)=0 or minimize L(w,b)이 되도록 하는 w,b 찾기이다
경사하강법(Stochastic Gradient Descent)
- 학습의 목적은 모델의 예측값과 실제 정답값의 차이를 최소화하는 파라미터(w,b) 구하기!
- loss가 작아질 수 있도록 파라미터를 조금씩 개선된 방향으로 업데이트해주는 녀석이 바로 “경사하강법”
- 임의로 초기화된 weight를 어떻게 바꾸어야 loss를 줄일까?
- 현재 weight값에서 loss에대한 (편)미분을 구함
- 미분의 기울기를 체크해서 기울기가 +라면 weight가 작아져야 loss도 줄어들것이니 weight값을 약간 줄여서 업데이트
- 미분의 기울기를 체크해서 기울기가 -라면 weight가 커져야 loss도 줄어들것이니 weight값을 약간 키우도록 업데이트 하면 됩니다.
- 경사(미분 기울기)내려가는 방향으로 파라미터 업데이트를 진행하기 떄문에 이런 이름이
- SGD(Stochastic Gradient Descent)
Summary
- loss함수란 모범다운과 예측값의 차이를 정량화하는 함수
- 학습의 목적은 loss가 가능한 작아지도록 하는 모델의 파라미터(weight, bias)를 찾는 것
- 경사하강법을 통해서 loss가 작아지도록 하는 파라미터의 업데이트 방향을 찾고, 파라미터를 해당 방향으로 약간 업데이트 하는 방법
- 경사하강법을 통해 파라미터를 업데이트를 반복하다 보면, 최적의 파라미터를 찾음
softmax
- softmax는 output layer에 적용되는 함수로 output뉴런의 결과값을 각 클래스가 정답일 확률로 변환해주는 역할을 함
- score에 대한 총합을 1로 맞추어서, class간 상대적인 비교가 가능하게 하는 softmax
Epoch
- 모든 training데이터를 한번씩 업데이트를 진행하면 한 epoch이 끝난 것
Iteration
Mini-batch
- 한 iteration을 진행할 training data의 예제의 묶음
하이퍼파라미터(Hyperparameter)
- 파라미터는 모델의 학습데이터를 보면서 데이터를 더 잘 맞출 수 있도록 최적화해나갈 weight나 bias와 같은것
- 우리가 조절하는 것이 아니라 loss값을 줄이기 위해 SGD를 통해 조금씩 고쳐 나감
- 사람이 설정하는 것이 아니라 데이터를 통해 자동 업데이트
- 하이퍼파라미터는 그 이외의 모든 사람이 설정하는 옵션값들
- neuron network 아키텍처는 어떻게 구성할지, layer는 몇개나 쌓을 것 이며, 한 later당 node수는 얼마나 많이 할 것인지.
- 나의 설정에 따라 인공신경망 구조가 깊고 뚱뚱하게, 아주 복잡해지거나 얇고 날씬해서 단순해짐
- 모델의 capacity(complexity)를 결정
- training동안 학습됮 ㅣ않음
- e.g learning rate, hidden size, layer수 mini-batch size, feautre수
learning rate(학습률)
- weight를 더 나은 방향으로 업데이트하려 한다면, 미분을 통해 기울기를 구하고, 그 기울기의 반대 방향으로 조금 이동시킨다면 loss가 더 낮아질 수 있음
- a : 업데이트의 크기, 폭을 결정, 양의 실수값
- 크게 설정할 수록 나는 파라미터를 크게 업데이트
- 작은 값으로 설정한다면, 조금씩 업데이트
Activation function
- 활성화 함수란? 인공신경망의 각 뉴런에 데이터를 가중합하고 난 뒤 취하는 함수를 의미
- neuron이 가중합을 하고 난 결과를 부드런 S자모양의 함수를 적용하여 0-1로 변환하는 sigmoide함수를 activation func으로 채택
- Relu(Reactified Linear Unit)
- 비선형함수. 음수값은 0으로 변환하고 양수값으 그대로 returb
- sigmoid의 단점을 개선
- 입력값을 0-1로 변환하는 계산하는 과정 복잡
- 가장 큰 문제는 `neuron의 가중치 결과가 몹시 크거나 작을경우 sigmoid의 gradient(기울기)가 거의 0에 가까워짐
- relus는 계산이 간편 가중합의 결과가 몸시 크거나 작아도 기울기가 0,1로 고정
- sigmoid를 쓰는 경우보다 6배정도 모델을 빠르게 수렴시키는 효과
참고
Continue reading
Step 1 : Create a new GitHub Repo
Step 2 : Initialize Git in the project folder
- terminal에서 추가하고 싶은 폴더로 이동하여 아래 command를 실행
Initialize the Git Repo
Add the files to Git index
git add command는 git에게 어떤 파일들이 commit에 포함될지 그리고 -A 의미는 “include all
Commit Added Files
git commit -m "added my project"
git commit command는 added된 new commit를 만들고 message와 함께 포함. commit을 이해하기 위해 future reference를 사용
Add new remote origin(in this case)
git remote add origin git@github.com:sammy/my-new-project.git
- git에서
remote는 remote version of the same repository, which is typically on a server software. origin은 remote server(you can have multiple remotes)의 default이름 git remote add origin는 이 repo의 기본 remote server의 URL을 추가하는 것
Push to GitHub
git push -u -f origin master
-f flag는 force. 이것은 자동으로 remote directory를 overwrite하는 과정.-uflag는 remote origin 설정. 이것은 git push 그리고 git pull를 나중에 특정 origin을 설정하지 않고 항상 push하게 해줌
All together
git init
git add -A
git commit -m "Addded my project"
git remote add origin git@github.com:sammy/my-new-project.git
git push -u -f origin masater
###
참고
Continue reading
What does a Loss function do ?
- measures how good the current guess is
What does the optimizer do?
What is Convergence?
- The process of getting very close to the correct answer
What does model.fit do?
- It trains the neural network to fit one set of values to another
What is a Convolution?
- A technique to isolate features in images
What is a Pooling?
- A technique to reduce the information in an image while maintaining features
How do Convolutions improve image recognition?
- They isolate features in images
After passing a 3x3 filter over a 28x28 image, how big will the output be?
After max pooling a 26x26 image with a 2x2 filter, how big will the output be?
Applying Convolutions on top of our Deep neural network will make training:
- It depends on many factors. It might make your training faster or slower, and a poorly designed Convolutional layer may even be less efficient than a plain DNN!
Using Image Generator, how do you label images?
- It’s based on the directory the image is contained in
What method on the Image Generator is used to normalize the image?
How did we specify the training size for the images?
- the target_size parameter on the training generator
- Every Image will be 300x300 pixels, with 3 bytes to define color
f your training data is close to 1.000 accuracy, but your validation data isn’t, what’s the risk here?
- You’re overfitting on your training data
Convolutional Neural Networks are better for classifying images like horses and humans because:
After reducing the size of the images, the training results were different. Why?
- We removed some convolutions to handle the smaller images
What is the name of the object used to tokenize sentences?
What is the name of the method used to tokenize a list of sentences?
Once you have the corpus tokenized, what’s the method used to encode a list of sentences to use those tokens?
- texts_to_sequences(sentences)
When initializing the tokenizer, how to you specify a token to use for unknown words?
If you don’t use a token for out of vocabulary words, what happens at encoding?
- The word isn’t encoded, and is skipped in the sequence
If you have a number of sequences of different lengths, how do you ensure that they are understood when fed into a neural network?
- They’ll get padded to the length of the longest sequence by adding zeros to the beginning of shorter ones
When padding sequences, if you want the padding to be at the end of the sequence, how do you do it?
- Pass padding=’post’ to pad_sequences when initializing it
What is the name of the TensorFlow library containing common data that you can use to train and test neural networks?
How many reviews are there in the IMDB dataset and how are they split?
- 50,000 records, 50/50 train/test split
How are the labels for the IMDB dataset encoded?
- Reviews encoded as a number 0-1
What is the purpose of the embedding dimension?
- It is the number of dimensions for the vector representing the word encoding
When tokenizing a corpus, what does the num_words=n parameter do?
- It specifies the maximum number of words to be tokenized, and picks the most common ‘n’ words
To use word embeddings in TensorFlow, in a sequential layer, what is the name of the class?
- tf.keras.layers.Embedding
IMDB Reviews are either positive or negative. What type of loss function should be used in this scenario?
When using IMDB Sub Words dataset, our results in classification were poor. Why?
Why does sequence make a large difference when determining semantics of language?
- Because the order in which words appear dictate their impact on the meaning of the sentence
How do Recurrent Neural Networks help you understand the impact of sequence on meaning?
- They carry meaning from one cell to the next
How does an LSTM help understand meaning when words that qualify each other aren’t necessarily beside each other in a sentence?
- Values from earlier words can be carried to later ones via a cell state
What keras layer type allows LSTMs to look forward and backward in a sentence?
What’s the output shape of a bidirectional LSTM layer with 64 units?
When stacking LSTMs, how do you instruct an LSTM to feed the next one in the sequence?
- Ensure that return_sequences is set to True only on units that feed to another LSTM
If a sentence has 120 tokens in it, and a Conv1D with 128 filters with a Kernal size of 5 is passed over it, what’s the output shape?
What is the name of the method used to tokenize a list of sentences?
If a sentence has 120 tokens in it, and a Conv1D with 128 filters with a Kernal size of 5 is passed over it, what’s the output shape?
What is the purpose of the embedding dimension?
- It is the number of dimensions for the vector representing the word encoding
IMDB Reviews are either positive or negative. What type of loss function should be used in this scenario?
If you have a number of sequences of different lengths, how do you ensure that they are understood when fed into a neural network?
- Use the pad_sequences object from the tensorflow.keras.preprocessing.sequence namespace
When predicting words to generate poetry, the more words predicted the more likely it will end up gibberish. Why?
- Because the probability that each word matches an existing phrase goes down the more words you create
What is a major drawback of word-based training for text generation instead of character-based generation?
- Because there are far more words in a typical corpus than characters, it is much more memory intensive
##
참고
Continue reading
Tensor Basic
FNN(Fully-connected Neural Network)
- 뉴런을 단계별로 층층히 연결하여 데이터를 흘려보내는 방식의 인공신경망
- Input.Hidden/Output layer들로 구성
- 세로로 묶인 일련의 뉴런의 묶음을 layer라고 부름
- 뉴런끼리 레이어간 빽빽하게 연결되어 있어서 이러한 형태의 layer를 Dense layer
Tensor
- tensor란 수학적인 개념으로 데이터의 배열
- tensor의 Rank는 간단히 말해서 몇 차원 배열인가를 의미
- 차원의 수는 Rank와 같은말
- matrix의 집합인 tensor는 당연히 3차원 부터 시작하니 최소 3이상의 수
- tensor는 일관된 유형(dtype이라고불림)을 가진 다차원 배열. 지원되는 모든 dtypes은 tf.dtypes.DType에서 볼수 있음
- Numpy에 익숙하다면, tensor는 일종의 np.arrays와 같음
- 모든 tensor는 python숫자 및 문자열과 같이 변경 불가능
- tensor 내용은 업데이트 불가능하며 새로운 tensor만 생성가능
- Rank/Type
- 0/scalar : [1]
- 1/vecotr : [1,1]
- 2/matrix : [[1,1],[1,1]]
- 3/3-tensor : [[[1,1],[1,2]]]
- n/n-tensor : etc
- tensor 생성방법 : np.array 또는 tensor.numpy 메서드를 이용하여 tensor를 numpy배열로변환
Tensor Shapes (형상정보)
- shape : tensor의 각 차원의 길이. the length of each the axes of a tensor
- rank : tensor 축의 수. number of tensor axes. a scalar has rank 0, a vector has rank 1, a matrix is rank2
- Axis or Dimension : a particular dimentsion of a tensor
- size : the total number of items in tensor.
ex)
rank_4_tensor = tf.zeros([3,2,4,5])
3 2 4 5
-> rank 4
-> 3 : axis 0
-> 5 : axis -1
print("Type of every element:", rank_4_tensor.dtype)
print("Number of dimensions:", rank_4_tensor.ndim)
print("Shape of tensor:", rank_4_tensor.shape)
print("Elements along axis 0 of tensor:", rank_4_tensor.shape[0])
print("Elements along the last axis of tensor:", rank_4_tensor.shape[-1])
print("Total number of elements (3*2*4*5): ", tf.size(rank_4_tensor).numpy())
*********************************************
Type of every element: <dtype: 'float32'>
Number of dimensions: 4
Shape of tensor: (3, 2, 4, 5)
Elements along axis 0 of tensor: 3
Elements along the last axis of tensor: 5
Total number of elements (3*2*4*5): 120
- axes 때때로 그들의 indices를 표현
Shape
- tensor가 어떻게 생겼는지를 표현하는 방식
- 대괄호 안에 각 차원의 길이(element)를 표기하면 됨
- mnist는 가로 세로 28픽셀을 갖는 행렬데이터이므로 [28,28]고 같이 shape를 표헌
- color 이미지의 경우 RGB의 세개의 값을 표현해야하므로 3Rank tensor
- 관례적으로 데이터 수는 shape의 맨앞에 써주는 것이 일반적
Manipulating Shapes
Reshaping a tensor is of a great utility
x = tf.constant([[1],[2],[3]])
print(x.shape)
*******output********
(3,1)
# you can convert this object into a Python list, too
print(x.shape.as_list())
# you can reshape a tensor to a new shape
reshaped = tf.reshape(x,[1,3])
참고
Continue reading
k8s reset하기
Continue reading
k8s multi-master HA 구성
Continue reading
How to identify and kill zombie/defunct processes in Linux without reboot
- Linux에서는 maximum process 개수가 잇고 그리고 process id가 존재
- maximum에 다다르면, 새로운 process를 시작이 불가능
- zombie process는
그들이 parent process로부터 적절하게 정리되지 않은 dead process이다 - process가 linux에 죽을때, 메모리로부터 모든것을 즉시 제거한다.
- process status는 EXIT ZOMBIE로 변하고 parent process는 child process로부터
SIGCHLD signal을 받는다 - parent process는 dead process의 exit status를 읽기 위해
wait() 시스템 콜을 호출 - parent process는 dead process로부터 정보를 얻는다
wait()이 호출 된 후, zombie process는 완전히 메모리부터 제거
- 위의 과정은 보통 굉장히 빨리 발생하고 system에 zombie process로부터 쌓이는 것을 보지 못함
- parent process가 적절히 프로그래밍 되지 않고, wait() 시스템 호출을 절대로 하지 않으면, 그것의 zombie children은 계속 메모리에 남는다
Continue reading
ps and htop - listeing and finding proceess
htop 프로그램은 더 유연하고 사용하기 쉬움- terminal에서 sorting column을 mouse로 지원
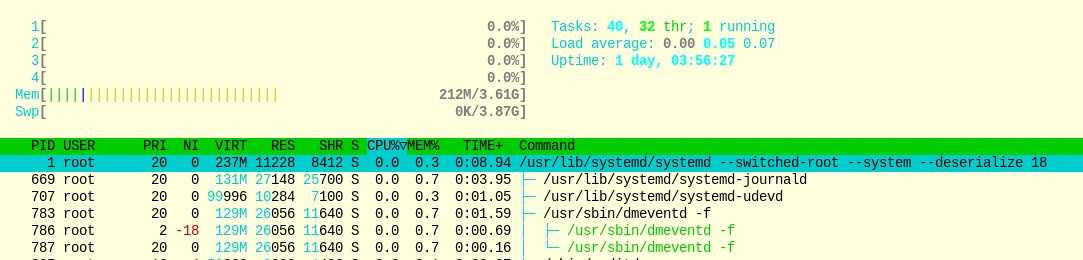
ss and netstat - what ports is that process using
netstat은 old way이고 요즘 배포판은 ss가 많이 적용ss -ntaupess -ntpl : listening port만 찾기 위함options
-n : lists processing using numeric address-t : list TCP connections-a : list all connections listening and establised-u : lists UDP connections-p : shows the process using the socket - probably the most useful-e : shows some extened information like the uid
Shell job control - fg/bg/jobs
Continue reading
Continue reading
Problem
 You are given an array prices where prices[i] is the price of a given stock on the ith day.
You are given an array prices where prices[i] is the price of a given stock on the ith day.
You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
Solution
- 첫번쨰날의 주식가격을 buy
- 항상 i번쨰 날에 주식을 sell하여 maxprofit 값을 계속 추적
- buy 값을 항상 비교하여 min값으로 갱신
Code
Continue reading
Collection - Counter
- Container에 동일한 값의 자료가 몇개인지를 파악하는데 사용하는 객체
A Counter is a dict subclass for counting hashable objects. It is an unordered collection where elements are stored as dictionary keys and their counts are stored as dictionary values. Counts are allowed to be any integer value including zero or negative counts. The Counter class is similar to bags or multisets in other languages.
collections.Counter()의 결과값은 dictionary 형태로 출력
1. Counter()의 다양한 입력값들
리스트(list)
- lst = [‘aa’, ‘cc’, ‘dd’, ‘aa’, ‘bb’, ‘ee’]의 요소 개수를 collections.Counter()를 이용하여 구할 수 있다. 출력 결과는 Dictionary형태로 반환하여 준다.
collections.Counter 예제 (1)
list를 입력값으로 함
import collections
lst = ['aa', 'cc', 'dd', 'aa', 'bb', 'ee']
print(collections.Counter(lst))
결과
Counter({'aa': 2, 'cc': 1, 'dd': 1, 'bb': 1, 'ee': 1})
딕셔너리(Dictionary)
collections.Counter()의 입력값은 Dictionary 형태로 넣어주면 결과 또한 Dictionary이다
collections.Counter 예제 (2)
dictionary를 입력값으로 함
import collections
print(collections.Counter({'가': 3, '나': 2, '다': 4}))
'''
결과
Counter({'다': 4, '가': 3, '나': 2})
'''
값=개수형태
collections.Counter()에는 값=개수형태로 입력이 가능하다. ``` collections.Counter 예제 (3) ‘값=개수’ 입력값으로 함 import collections c = collections.Counter(a=2, b=3, c=2) print(collections.Counter(c)) print(sorted(c.elements()))
##결과 Counter({‘b’: 3, ‘c’: 2, ‘a’: 2}) [‘a’, ‘a’, ‘b’, ‘b’, ‘b’, ‘c’, ‘c’]
#### 문자열string
- 문자열 입력시 `{문자 : 개수}` dictionary형태로 반환
### 2. Counter의 메소드들
#### update()
- counter값의 갱신 하는 것 의미.
#### elements()
> Return an iterator over elements repeating each as many times as its count. Elements are returned in arbitrary order. If an element’s count is less than one, elements() will ignore it.
- 입력된 값의 요소에 해당하는 값을 풀어서 반환. element는 무작위로 반환 대소ㅜㄴ자를 구분하여 `sorted()`을 이용하여 정렬해줄 수 있다
collections.Counter 예제 (6) elements() 메소드 사용 import collections c = collections.Counter(“Hello Python”) print(list(c.elements())) print(sorted(c.elements())) ‘’’ 결과 [‘n’, ‘h’, ‘l’, ‘l’, ‘t’, ‘H’, ‘e’, ‘o’, ‘o’, ‘ ‘, ‘y’, ‘P’] [’ ‘, ‘H’, ‘P’, ‘e’, ‘h’, ‘l’, ‘l’, ‘n’, ‘o’, ‘o’, ‘t’, ‘y’] ‘’’ c2 = collections.Counter(a=4, b=2, c=0, d=-2) print(sorted(c.elements())) ‘’’ 결과 [‘a’, ‘a’, ‘a’, ‘a’, ‘b’, ‘b’] ‘’’
#### most_common()
> Return a list of the n most common elements and their counts from the most common to the least. If n is omitted or None, most_common() returns all elements in the counter. Elements with equal counts are ordered arbitrarily
- `most_common`은 입력된 값의 요소들 중 빈도수가 높은 순으로 상위 개를 list안의 tuple로 반환
collections.Counter 예제 (7) most_common() 메소드 사용 import collections c2 = collections.Counter(‘apple, orange, grape’) print(c2.most_common()) print(c2.most_common(3)) ‘’’ 결과 [(‘a’, 3), (‘p’, 3), (‘e’, 3), (‘g’, 2), (‘,’, 2), (‘r’, 2), (‘ ‘, 2), (‘n’, 1), (‘l’, 1), (‘o’, 1)] [(‘a’, 3), (‘p’, 3), (‘e’, 3)] ‘’’ ```
참고
Continue reading
Dictionary
docs 참고
- 정렬되지 않은 값들을 넣는다
- map과같이 값들을 저장
- key, value 쌍으로 이루어짐
- key는 unique
생성
- { } (braces)으로 생성
- comma로 구분
- mixed key로 생성가능
defualtdict
- from collections import defaultdict
- dict클래스의 subclass이다
- 차이점은 keyerror를 일으키지 않는다
- defaultvalue를 제공
dic_list=default(list)
for src,target in tickets:
dic_lista[src].append(target)
sorted vs sort
- sort는 자체적으로 리스트를 정렬
- sorted는 정렬하여 새로운 리스트 생성
dictionary 정렬
- key 기준 정렬
- key,value 알파벳순 정렬
- key, value 기준으로 정렬 => value,key순서대로
sorted(dic_list.items(),key=lambda x : (x[1],x[0]))
정렬
- 정렬문서 참고
- sorted(sorted(count_dict.keys()), key=lambda x: count_dict[x])
- 내림 차순 정렬 reverse=True 추가
- sorted(iterable,key,reverse)
sorted
count_dict = {}
for num in row:
if num == 0:
continue
if num in count_dict:
count_dict[num] += 1
else:
count_dict[num] = 1
next_row = []
for key in sorted(sorted(count_dict.keys()), key=lambda x: count_dict[x]):
next_row.append(key)
next_row.append(count_dict[key])
next_arr.append(next_row)
max_len = max(max_len, len(next_row)
sorted(sorted(count_dict.keys()), key=lambda x: count_dict[x]):
접근
- key로 접근가능
- ex) Dict[‘name’]=1
- get 메소드로 접근가능
- ex) Dict.get(‘name’)=1
삭제
METHODS DESCRIPTION
- copy() They copy() method returns a shallow copy of the dictionary.
- clear() The clear() method removes all items from the dictionary.
- pop() Removes and returns an element from a dictionary having the given key.
- popitem() Removes the arbitrary key-value pair from the dictionary and returns it as tuple.
- get() It is a conventional method to access a value for a key.
- dictionary_name.values() returns a list of all the values available in a given dictionary.
- str() Produces a printable string representation of a dictionary.
- update() Adds dictionary dict2’s key-values pairs to dict
setdefault() Set dict[key]=default if key is not already in dict - keys() Returns list of dictionary dict’s keys
- items() Returns a list of dict’s (key, value) tuple pairs
- has_key() Returns true if key in dictionary dict, false otherwise
- fromkeys() Create a new dictionary with keys from seq and values set to value.
- type() Returns the type of the passed variable.
- cmp() Compares elements of both dict.
Continue reading
Python Collection Default dict
python collections 이란?
python collections are specialized container datatypes providing alternatives to Python’s general purposd built-in conatiners dict,list,set and tuple
- python의 built-in type에 mechanisim이 추가됨
So What exactly is DefaultDict?
defaultdict는 모든 일반적인 목적으로 만든 dictkeyerror를 일으키지 않음(일반적인 dict는 handling code를 작성해야하지만 내부에 이미 구현)defaultdict는 다음 사항이 적용- access할때 dictionary에 key가 미존재시
keyerror를 일으키지 않음 defaultdict 생성시 default value를 제공해서 자동으로 key가 생성되게함
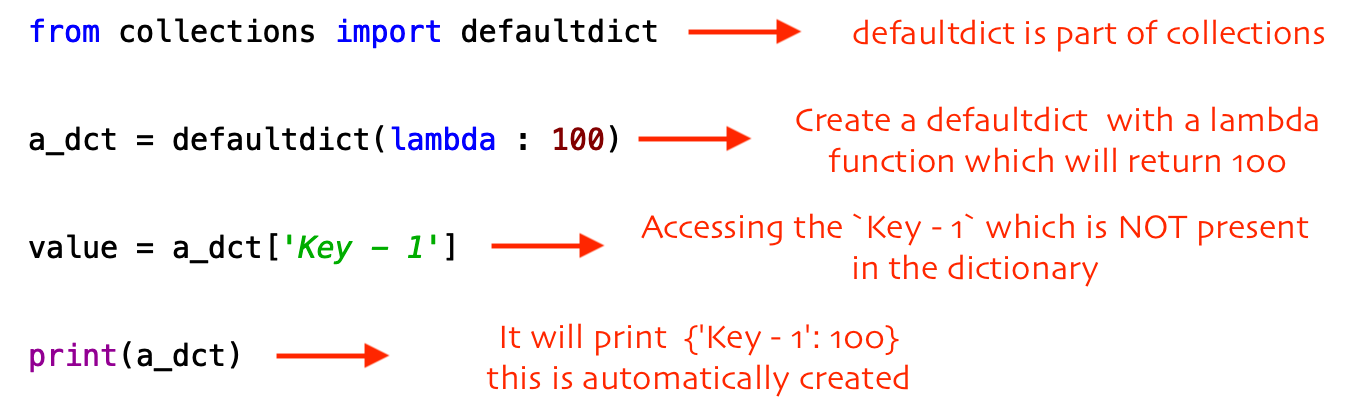
default value 생성
Continue reading




