Python Pandas DataFrame Basics: How To Perform Indexing And Slicing
1. Introduction
pandas는 data analysis를 위한 오픈소스 python 라이브러리
spread-sheet같은 data를 아래와 같은 기능을 하도록 지원
fast-data loading
manipulating
aligning
mering
among other functions
pandas의 이런 기능을 잘 이용하기 위해서 pandas는 2가지 새로운 type data를 이용
Series
Dataframe
Series: Pandas series are basically dataset having only one row or one column. Means, if we filter out only one row or only one column from a dataframe, its called “series”.
dataframe으로부터 one row or one column을 가지는 dataset
Dataframe: The DataFrame represents your entire spreadsheet or rectangular data, whereas the Series is a single column of the DataFrame.
전체 data를 가짐 반며에 Series는 Dataframe의 one column or one row
Dataframe은 Series Object들의 dictionary or collection으로 취급
Dataframe example
Series example
위의 dataframe에서 3번째 index를 추출 또는 one row를 추출하면 그것이 series object가 된다
filtering one row
slicing one column
2.Dataframe Explained in Detail
2.1 Get the number of rows and columns
df.shape은 첫번째 row은 tuple을 반환 그리고 2번째 row부터 column을 반환
shape는 dataframe의 attribute이기 때문에 function이나 method가 아님
shape[0] : 행
shape[1] : 열
2.2 Get the column names
df.columns method는 dataframe의 column명을 가져옴
2.3 Get the dtype of each column
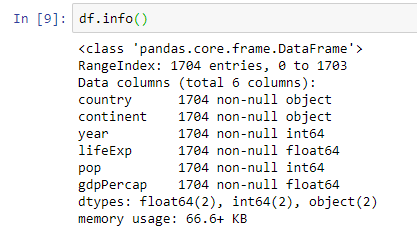
2.4 Get more information about our data
2.5 Pandas Type Versus Python Types
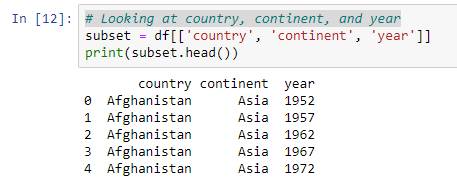
3. Lookig at columns, rows, cells
data가 너무 많으므로 handling할 경우, subsets of data를 보고 data를 handling한다 —
3.1 Subsetting Columns
3.1.1 Subsetting Columns by name
data의 특정 column만 보고 싶은 경우 square bracket를 사용
여러 column을 subset으로 지정
3.1.2 Subsetting Columns by Range
built-in range function을 활용하여 생성가능
특정 begin and end value값을 지정하여 해당 범위 subset자동 생성
3.2 Subsetting Rows
rows은 multiple way로 subset 생성가능
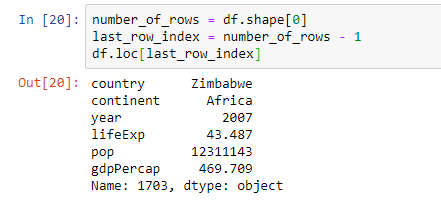
3.2.1 Subset Rows by Index Label : loc
loc[integer]를 활용하여 특정 row의 data를 가져옴
3.2.2 Subset Rows by Row Number: iloc
iloc는 loc와 유사하지만, row index number를 활용
index label이 같으면 iloc와 loc과 같은 동작으로 사용
index label은 row number가 필요
3.3 Mixing it up : Subsetting Multiple rows and colums
loc그리고 iloc attribute는 subset of columns, rows, or 둘다 가져 올 수 있음
comma의 left : subset의 row values
comma의 right : subset의 column values
df.loc[[rows],[columns]] or df.iloc[[rows],[columns]]
dicionary와 같은 container을 지원. 특정 값에 hash를 적용한 key를 포함. key, idex 둘다 접근 가능. tuple의 성질을 가졌고, tuple은 일반적으로 index로 접근하므로 직관적이지 않음. namedtuple은 field의 key(이름)을 붙여 사용 가능
Access options
Access by index : The attribute values of namedtuple() are ordered and can be accessed using the index number unlike dictionaries which are not accessible by index.
Access by keyname : Access by keyname is also allowed as in dictionaries.
using getattr() :- This is yet another way to access the value by giving namedtuple and key value as its argument.
Python에서 module은 python code를 포함하는 파일 그것의 .py라는 suffix가 붙음 일반적으로 관련 class또는 function을 모듈에 넣고 전체프로그램을 다른 module로 분리하는것이 좋은 programming practice이다
아래에는 module을 잘 사용하고 관리하기 위한 좋은 3가지 skill에대한 소개
1. Import Python Modules Skillfully
(1) Don’t use an asterisk to import all things at once
모든 모듈을 import할떄 가장 기본적인 방법은 asterisk를 사용하는 것 from module_a import *
그러나 위의 방법은 무엇을 import했는지 불명료하고 bug를 일으킬 가능성이 있음
현재 파일의 name이 다른 imported name과 총동 가능성
imported module에 새로운것을 추가하면, 모든 new names은 또한 import된다. name conflict를 일으킬 가능성이 높음
필요한 모듈부분만 import 하는것은 좋은 습관이다
(2) Give it a nickname for convenience
datascientist라면 아래코드가 친숙할 것이다
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
as keyword를 alias를 줌으로써 긴이름의 module을 더 짧게사용
(2) Use relative imports smartly
dots.를 사용함으로써 현재 파일의 상대 경로 모듈을 더 효과적으로 가져옴
from . import module_a
from .. import module_b
single dot은 module_a는 현재 파일의 위치에서 같은 directory에서 import(its’s siblings)
two dots은 module_b 현재 파일의 위에서 상대적으로 위의 directory에서 import(it’s parent)
2. Execute Python Moduels as Scripts
importing module에다가 또한 우리는 module을 개별적으로 script같이 실행가능
아래는 예시 test.py라는 모듈이 있고 아래 code가 포함 print("Yang Zhou")
terminal에서 module을 실행 시킬때, 아래와 같은 command를 입력
위에 예와 같은이 python을 module이름 앞에 붙여서 실행
text.py가 function or class를 포함시 우리는 mainfunction을 포함하여 실행
def output_author(name):
print(name)
if __name__ == "__main__":
import sys
output_author(name=sys.argv[1])
module이 다른 module에 import 되면 main function은 실행하지 않으므로 유연성을 제공
2. Manage Python Modules by Packages
python package는 다른 module들을 grouping시킴. logically related module들을 package에 넣는것은 좋은 습관 !(blog)[https://miro.medium.com/max/568/1*iy9OaOsJ9nU9OL2r702aBw.png]
위의 예시에서는 blog 그리고 mysite라는 2개의 python package그리고 migration이라는 blog의 sub package가 존재 package를 사용함으로써 프로젝트를 좀더 논리적으로 명확하게 관리가능
dicionary와 같은 container을 지원. 특정 값에 hash를 적용한 key를 포함. key, idex 둘다 접근 가능. tuple의 성질을 가졌고, tuple은 일반적으로 index로 접근하므로 직관적이지 않음. namedtuple은 field의 key(이름)을 붙여 사용 가능
Access options
Access by index : The attribute values of namedtuple() are ordered and can be accessed using the index number unlike dictionaries which are not accessible by index.
Access by keyname : Access by keyname is also allowed as in dictionaries.
using getattr() :- This is yet another way to access the value by giving namedtuple and key value as its argument.
Design a data structure that follows the constraints of a Least Recently Used (LRU) cache.
Implement the LRUCache class:
LRUCache(int capacity) Initialize the LRU cache with positive size capacity.
int get(int key) Return the value of the key if the key exists, otherwise return -1.
void put(int key, int value) Update the value of the key if the key exists. Otherwise, add the key-value pair to the cache. If the number of keys exceeds the capacity from this operation, evict the least recently used key.
Follow up: Could you do get and put in O(1) time complexity?
Solving
LRUCache를 구현하는데 O(1) Time Complexity로 구현
순서가 있는 OrderedDict로 구현
cache를 조회 시 (get)
key 존재 시 : 조회한 값을 맨 오른쪽으로 이동 및 값을 return
key 미존재 시 : -1를 return
cache에 data를 입력 시(put)
key 존재 시 : data를 맨 오른쪽 이동(조회 하였으므로)
key 미존재 시 :
capacity 미만 : 값을 추가
capacity 초과 : LRU(Least Recently Used)값을 삭제 및 신규 값 추가
Kubernetes(약어 k8s)란 Container Orchestration 플랫폼이다. container화 된 워크로드/서비스/애플리케이션을 관리하기 이식성 있고, 확장 가능한 오픈 소스 플랫폼. 시스템에 배포 가능한 애플리케이션의 구성 요소가 많아짐에 따라 모든 구성의 요소를 관리를 용이하기 위해 사용.
리눅스(Linux)는 리누스 토발즈가 커뮤니티 주체로 개발한 컴퓨터 운영 체제입니다. 리눅스(Linux)는 UNIX운영체제를 기반으로 만들어진 운영체제 입니다. 리눅스(Linux)는 유닉스(UNIX)와 마찬가지로 다중 사용자, 다중 작업(멀티태스킹), 다중 스레드를 지원하는 네트워크 운영 체제(NOS)입니다.
리눅스의 원형이 되는 UNIX가 애초부터 통신 네트워크를 지향하여 설계된것처럼 리눅스 역시 서버로 작동하는데 최적화되어있습니다. 고로 서버에서 사용되는 운영체제로 많이 사용되고 있습니다.
Linux특징
리눅스는 유닉스와 완벽하게 호환가능합니다.
리눅스는 공개 운영체제입니다. 오픈소스이므로 누구든지 자유롭게 수정이 가능합니다.
리눅스는 PC용 OS보다 안정이며 보안쪽면에서도 PC용 OS보다 비교적 우수한 성능을 가지고 있습니다.
리눅스는 다양한 네트워킹 기술을 제공하고 있으며 서버용 OS로 적합합니다.
배포판이 아닌 리눅스 그 자체는 무료입니다.
Linux 종류
대표적인 계열이 레드햇 계열과 데비안 계열
레드햇 계열 : Redhat, Centos
데비안 계열 : Ubuntu
REDHAT계열
레드햇계열은 레드햇이라는 회사에서 배포한 리눅스를 말합니다. 2003년까지는 오픈소스 라이선스로 진행하다가 이후 상용화되었습니다. 레드햇 리눅스는 배포판 중에서 가장 인기가 많습니다. 커뮤니티가 아닌 회사에서 관리하는 레드햇계열의 리눅스는 다른 리눅스 배포판에 비해 패치가 빠르며 내장되어있는 유틸리티의 양도 많고 관리툴의 성능도 우수합니다. 또 호환성면에서도 나무랄데가 없지요. 여러모로 장점이 많습니다. 레드햇 계열의 리눅스에는 페도라와 센토스가 있는데 오늘날에는 페도라보다는 센토스를 더 많이 사용하는 추세입니다.
CENTOS
CentOS는 Community Enterprise Operating System 의 약자로 Red Hat이 공개한 RHEL을 그대로 가져와서 Red Hat의 브랜드와 로고만 제거하고 배포한 배포본입니다. 사실상 RHEL 의 소스를 그대로 사용하고 있기에 RHEL 과 OS 버전, Kernel 버전, 패키지 구성이 똑같고 바이너리가 100%로 호환됩니다. 무료로 사용 가능하지만 문제 발생시 레드햇이라는 회사가 아닌 커뮤니티를 통해 지원이 되므로 다소 패치가 느린감이 없지않아 있습니다. 특히 서버용 운영체제로 인기가 매우 높으며 서버용으로 리눅스를 운영할 목적이라면 아마 대부분 이 센토스OS를 사용하는것이 대부분일 것입니다.
데비안계열
데비안은 온라인 커뮤니티에서 제작하여 레드햇보다 더 먼저 배포되어 시장을 선점하였습니다. 이 데비안에서 파생되어진 OS를 데비안 계열이라고 부릅니다. 하지만, 자발적인 커뮤니티에서 만드는 배포판이라 전문적인 회사에서 서비스를 했던 레드햇계열에 비해 사후지원과 배포가 늦고 내장 유틸들의 성능이 레드햇계열에 비해 부족한감이 있어 오랫동안 레드햇에 밀렸었습니다. 하지만 현재는 무료 개인사용자 서버용으로 인기가 매우 높으며 최근에는 지속적인 업데이트를 거친 결과 레드햇계열에 비해 결코 성능이나 뒤쳐지지 않습니다. 그리고 넓은 유저층을 가지고 있는 데비안계열은 그 사용법이 온라인 웹사이트나 커뮤니티에 자세히 기술되어 있다는 점이 진입장벽을 낮추어 초보 리눅스유저들이 접근하기 쉬운 OS라고 할 수 있겠습니다.
UBUNTU
영국의 캐노니컬이라는 회사에서 만든 배포판으로 쉽고 편한 설치와 이용법 덕분에 진입장벽이 낮아 초보자들이 쉽게 접근할 수 있으며 데스크탑용 리눅스 배포판 가운데서 가장 많이 사용되어지고있는 배포판입니다. 개인용 데스크톱 운영체제로 많이들 사용합니다., 서버용으로도 기능이 부족하거나 성능이 딸리지는 않습니다만 서버용 리눅스 점유율로 볼때 센토스에 많이 밀리는것은 사실입니다. 서버는 센토스 데스크톱으로는 우분투라고 생각하시면 될듯 하네요.
Assertions or assert statement are build into python and are a tool for debugging
try to assert its authorityt over the rest of the code wher checking for a condititon specified by the programmer
example
speed라는 변수가 0이상인지를 체크할때, True이면 아무일도 발생 안하고 프로그램 정상실행. condititon이 faile이면 AssertionError를 일으킴
일반 예외처리와 다른점?
if try except구문을 사용한 예외처리와 다른 역할을 함
File Not Found와 같은 예상되는 에러 조건을 검사하기 위해 사용되는 것은 올바른 활용 방식이 아님
예상하지 않은 프로그램의 상태를 확인하기 위해 활용해야함
구문의 조건을 만족하지 않으면 프로그램이 정상적으로 실행되지 않고 종료되는데, 이는 프로그램의 버그가 있다는 것을 의미
런타임 환경이 아닌 디버깅 환경에 도움을 주는 역할
Syntax
assert condtition , erroe_message(optional)
Parameter
condition : the boolean condititon returning true/false
error_message : the optional argument to be printed in console in case of Assertion Error
Given a signed 32-bit integer x, return x with its digits reversed. If reversing x causes the value to go outside the signed 32-bit integer range [-231, 231 - 1], then return 0.
Assume the environment does not allow you to store 64-bit integers (signed or unsigned).
Solution
1. arithmetic
pop/push 연산을 통하여 마지막 one digit부터 reverse 숫자를 구함. overflow check! 필수