(3) The History and Evolution of Open Table Formats
The History and Evolution of Open Table Formats
The Origin of Table Formats
- 현대판 database 개념은
가 1970년에 발표한 Relation Model` 논문에서 영감을 받아 관계형 DB가 발명되면서 등장
- 그 이후로
Table Format은 선구적인 System R과 같은 관계형 DB관리시스템에서 구조화된 데이터를 관리하고 작업하기 위한 주요추상화 개념이 되었음
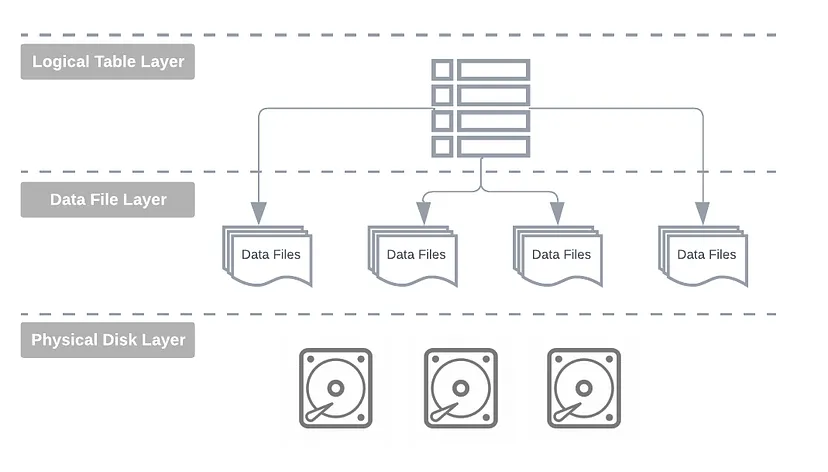
Table Format Abstraction
- logical dataset : 데이터 테이블은 디스크에 저장된 물리적 파일을 추상화한 계층으로, 통합된 2차원 표 형식뷰를 제공
- storage engine은 다양한 객체로부터 record들을 결합하여 dataset를 만들고 이를 하나 이상의 논리적 테이블로 최종사용자에게 표시
- 이러한 logical table은 애플리케이션과 사용자로부터 데이터의 물리적 특징을 숨길 수 있다는 장점을 제공
- 최근에
open table format에 대해 많이 들어봤는데 대단한것인지 혹은non-open,open그리고closed format과의 차이점을 알아보자
Relational Table Format
- 빅데이터 그리고 Apache Hadoop이 2000 중반에 나타나기전 DBMS(Database Management Systems)
은monolithic architectural design을 고수했음 - 이 architecture는 tightly coupled, interconnected layers 특징을 가지고 있음
- 각각의 layers는 database의 동작을 위한 특정한 functioon을 가지고 있음
- 구성요소들은 single unified system을 형성하기 위해 결합되었음
- storage layer는 특히 data persistence측면을 관리
- 이 구조의 핵심은 Storage Engine. 이 구성요소는 가장 최하층의 추상화 레벨이고, 디스크의 데이터에 대한물리적 구성 및 관리를 감독
What’s the implication?
- 이 디자인은 interoperability(상호 운용성)이 부족
- DB파일을 다른 시스템에 복사하거나 python과 같은 일반언어를 사용하여 처리할 수 없음
일반 쿼리엔진을 db의 os파일에 지정하여 데이터와 상호작용도 불가능
- 이러한 제약을 가만할때, 오늘날의 OTF(Open Table Format)같은 개념이 존재하지 않음
- 기존 DB는 특정 구현과 긴밀하게 통합된 독점적인 저장 형식을 사용
Hadoop and Big Data Revolution
1970년대부터 2006을 되돌아보면 BIG Data Revolution이 일어 났고
Apache Hadoop project가 Yahoo로부터 탄생하면서 db가 분해 disassembly of database systems- 주요한 architectural breakthrough(아키텍처 혁신)는 the decoupling of storage and compute(스토리지와 컴퓨팅의 분리)
이 아키텍처 변경으로 인해 HDFS 분산파일 시스템이 관리하는 commodity hardware(저렴한 상용 하드웨어)에서 CSV,JSON,Avro 및 Parquet과 같은 일반하된 semi-structured된 텍스트 기반 및 바이너리 형식으로 방대한 양의 데이터 저장이 가능
- 데이터는 local file system에 저장되고, 분산 처리 framework (MapReduce, Pig, Hive, Impala 그리고 Presto)과 같은 선택하여 처리 가능
이는 유연하지 않고 비싼 monolithic storage system과 독점 데이터웨어하우스에서 game-changer
- 그러나 진정한 혁신 AMPLab co-director Michael Franklin에서 언급한것 과같이 새로운 분리 아키텍처의 결과로 data independence(데이터 독립성)
The real breakthrough was the seperation of the logical view you have of the data and how you want to work with if, from the physical reality of how the data is actually stored
- 그래서 당시에 BigData was such Big Hype
- 오늘날 hype surrounds Generatvie AI과 비슷한 레벨
- 그것은 그 뒤를 이은 open data ecosystems에 큰 영향을 줌
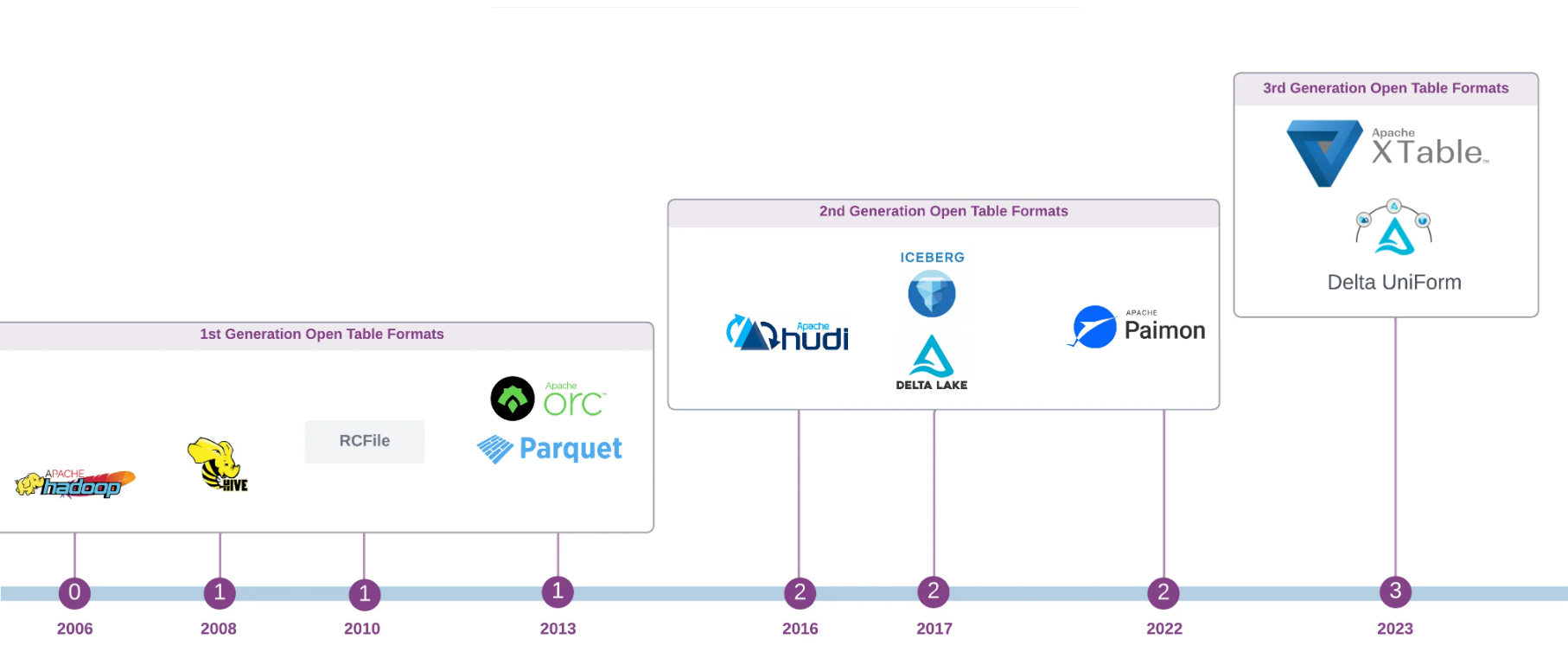
1st Generation OTF — The Birth of Open Table Format
Apache Hadoop의 최초 릴리스는 데이터엔지니어에게 상당한 과제를 안겨줌
- Java를 사용하여 MapReduce로직에서 데이터 분석 및 처리 워크로드를 표헌하는 것은 복잡하고 시간이 많이 걸림
- 게다가 Hadoop에는 파일시스템의 데이터 세트에 대한 스키마를 저장하고 관리하는 메커니즘이 부족
- 이러한 격차를 줄이기 위해 초기의 영향 있는 Hadoop 채택자인 Facebook(현재 meta)는 Hive프로젝트를 시작
- 목표는 기존 RDMBS에서 익숙한 SQL과 테이블 구조를 Hadoop 및 HDFS 생태계 도입
- 주요한 차이점은 새로운 아키텍처적 접근
Being build on top of the decoupled physical layer, leveraing open data formats stored on HDFS distributed file system
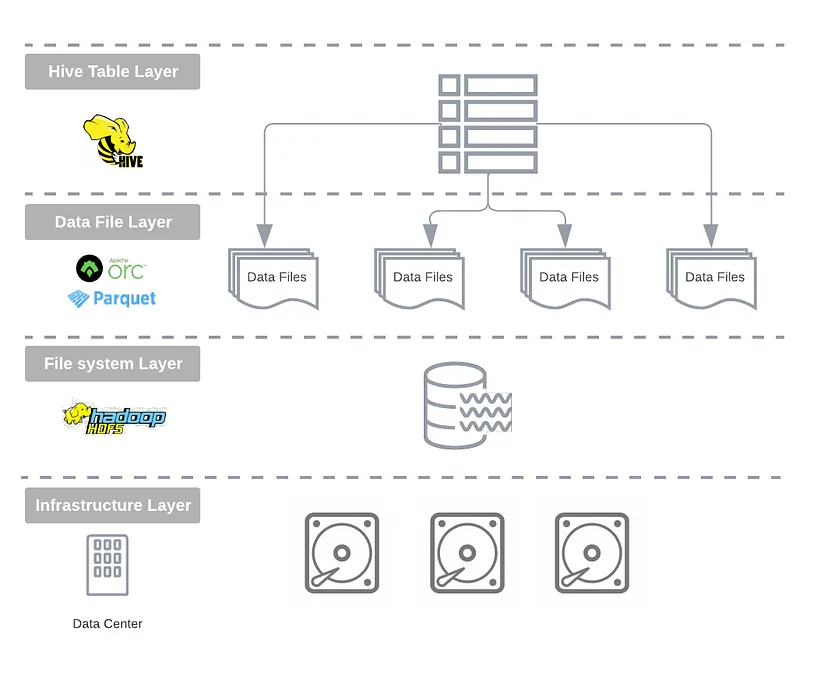
Impact of Apache Hive
- Facebook은 2008년에 HIVE를 오픈소스화 시킴. 몇년 후 Cloudera(저명한 Hadoop 벤더)가 Impala를 개발
- Apache Hive그리고 Impala가 Hadoop stack에 도입되면서, open file format기반의 the open table foramt개념이 등장
- directory기반 partitioning과 함께 Hive open table는 Hadoop 생태계 내에서 data ingestion, data modeling, 그리고 managment의 주요 추상화가 되었음
Evolution of Columnary Binary File Formats
- 또 다른 중요한 발전은 효율적인 columnar open file format등장. 이것은 Apache Hive 프로젝트의 1세대 columnar binary serialisation framework인 RCFiles로부터 시작
- 이후의 혁신은 2013년에 출시된 RCFile의 개량된 버전인 Apache ORC와 Twitter와 Cloudera의 공동작업으로 역시 2013년에 출시된 Apache parquet이 있음
- 이러한 new open file foramt은 Hadoop위의 OLAP기반의 workload의 성능을 획기적으로 향상시켜 데이터레이크 직접 OLAP저장 엔진을 구축할 수 있는 기반을 만듬
- 그 이후 ORC그리고 parquet은 데이터레이크에서 저장된 데이터를 관리하는 데 있어서 사실상 de facto(표준) open file format되었으며 parquet이 더 인기를 얻고 생태계에서 더 폭 넓은 채택과 지원을 받음
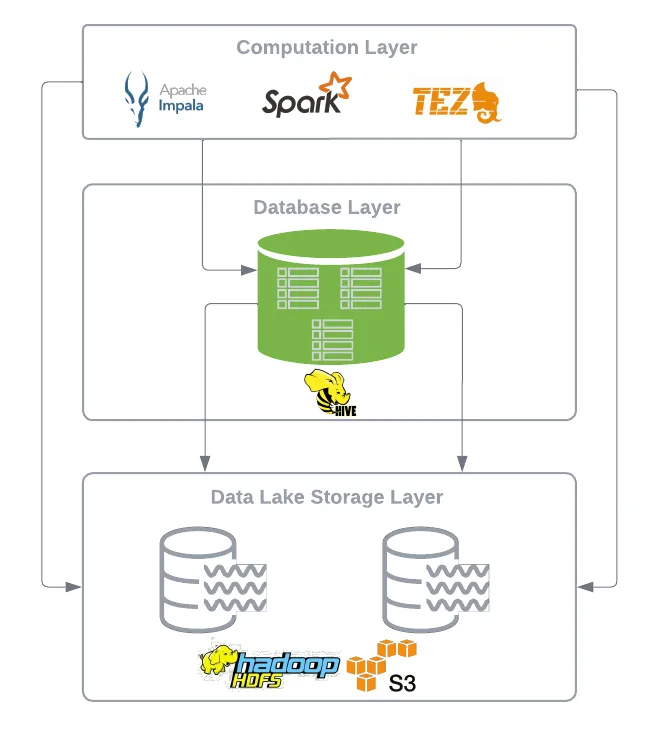
- 다음은 Hive table format이 어떻게 구조화되었는지 상세하게 살펴하고 그전에 Hive와 Impala가 사용하는 물리적 디자인을 일반화해보면.
- 이 디자인은 file system의 directory 계층구조에 크게 의존. 이를 directory-oriented table format이라고 부름
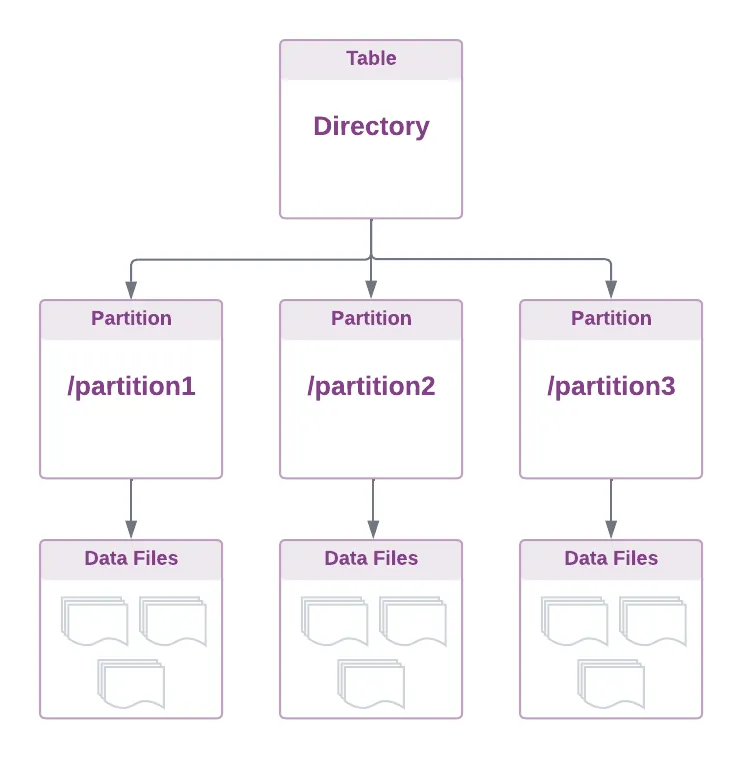
Directory-oriented Table Formats
- HDFS(데이터레이크)와 같은 분산 파일 시스템에서 데이터를 테이블로 처리하는 간단한 방법은 테이블을 디렉터리에 투사하는것 directory에는 data file 그리고 sub-directory(i.e partition)이 포함
The core principle is to organise data files in a **directory tree**. In essence, a table is just a collection of files tracked at the directory level, accessible by various tools and compute engine
- 여기서 중요한 요소는 이 아키텍처는 본질적으로(tied to the physical file system layout)
- 데이터 관리를 위한 파일 및 디렉터리 작업에 의존. 이는 hadoop이 시작된 이래로 데이터레이크에 데이터를 저장하는 표준 관행
What is the implication for Query Engines?
- 테이블 파티션이 sub-directory로 표현되므로, query engine은 query planning 단계동안 적절한 data file을 식별하기 위해 하위 디렉터리로 표현된 각 파티션을 구문 분석하고 스캔하는 것은 쿼리엔진의 책임
- 물리적인 파티셔닝은 테이블 레벨에서의 논리적인 파티셔닝과 강력하게 결합되어 있음을 의미
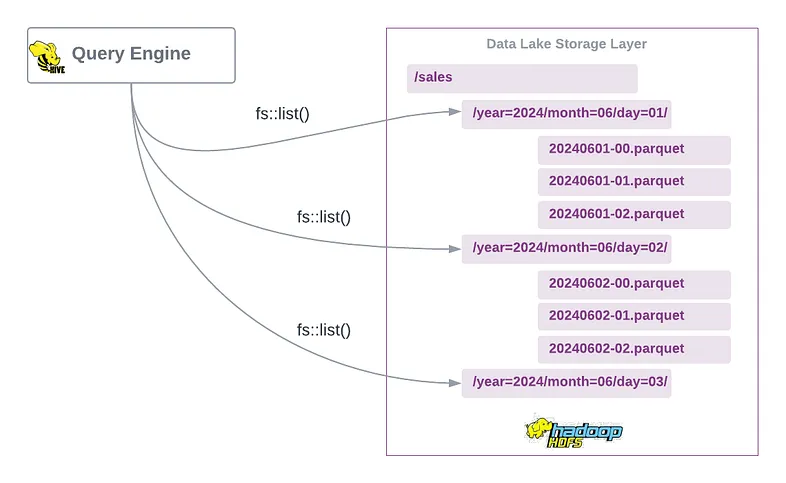
Hive Table Format
Apache Hive가 directory-oriented table format이라고 말하는 것은 타당. 파일을 테이블과 파티션에 매핑 시키기 위해 file system의 API에 의존 결과적으로 Hive는 분산 파일 시스템 내의 데이터의 물리적 레이아웃에 크게 영향을 받음
Hive는 field name과 value를 사용하여 파티션 디렉터리를 만드는 own partitioning schema(자체 파티셔닝 체계)를 사용 그것은 (Metastore라고 불려진 RDMS에서 schema, partition 그리고 다른 metadata를 관리
지금까지 Hadoop+Hive의 중요한 변화는 다음과 같음
기존의 전통적인 일체형 DB(traditional monolithic database)와 달리, Hadoop과 Hive의 분리된 접근 방식은 다른 쿼리 및 처리엔진이 Hive 엔진의 metadata를 사용하여 HDFS에서 동일한 데이터를 처리 할 수 있도록 함
이는 새로운 데이터 아키텍처와 기존 DBMS시스템간 또다른 주요한 차이점으로 이어짐
기존 시스템은 테이블 정의와 같은 데이터와 metadata를 긴밀하게 결합하는 반면, 새로운 paradigm은 이들은 불리 This decoupling은 great flexibility를 제공
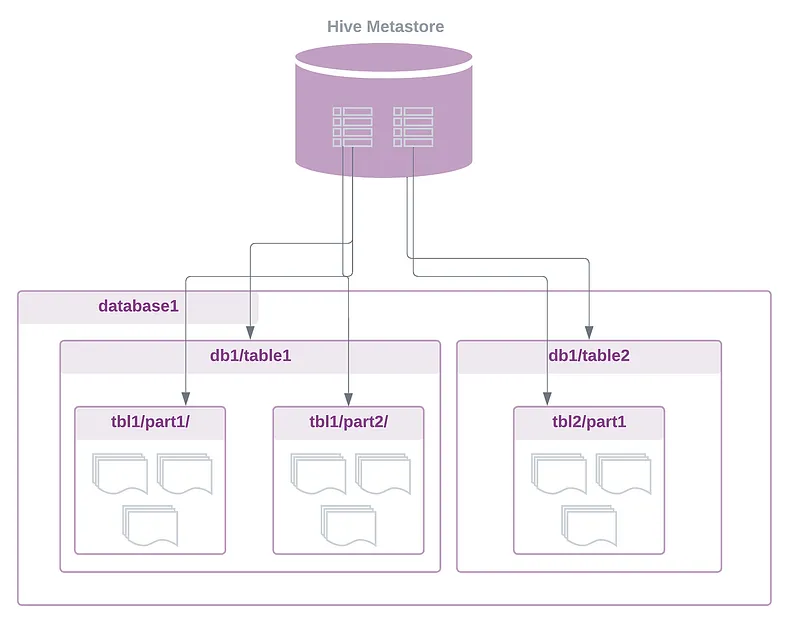
게다가 centralised schema registry(such as Hive metastore which has become the de facto standard)를 사용하면 Spakr, Presto/Trino등 다른 processing engine이 구조화된 표형식의 데이터와 상호 작용 가능
registry내 테이블 metadata에 엑세스함으로써, query engine은 기본 storage 계층의 파일 위치를 파악, 파티셔닝 체계를 이해하고, 자체적인 읽기와 쓰기 작업 수행가능
Drawbacks and Limitations and the Directory-oriented and Hive table Format
- 지난 10년동안 Hive는 Hadoop platform에서 가장인기 있는 테이블 형식으로 군림
- Uber,Facebook,Netflix과 같은 거대 기술 기업은 데이터를 관리하기 위해 Hive에 크게 의존
- 그러나 데이터 플랫폼을 확장하면서 Hive가 적절하게 해결할 수 없는 상당한 확장성 및 데이터 관리 문제에 직면
- 이러한 기술 회사의 엔지니어들이 대안을 모색하게 된 계기가 된 directory-orientied table format 그리고 Hive style table의 단점 몇가지 살펴보자
- High Dependency on Underlying File System
- 이 아키텍처는 atomicity(원시성),concurrency control(동시성 제어) 그리고 conflict resolution(충돌 해결)과 같은 필수적인 보장을 제공하기 위해 기본 storgae시스템에 크게 의존
- aws s3의 atomic rename 없는것과 같이 이러한 속성이 없는 파일시스템 사용자 지정 해결방법이 필요
- File Listing Performance
- directory 그리고 file listing operation이 성능 bottleneck현상이 될 수 있으며, 특히 대규모 쿼리 실행시 그렇다.
- aws s3와 같은 Cloud Object는 directory style listing operation에 상당한 제약을 가한다(ex operation당 1000개의 object s3 list 제한)
- Query Planning Overhaed
- HDFS와 같은 분산 파일시스템에서 전체 file 및 partition 목록이 필요하기때문에 query plan에 많은 시간이 소요
- High Dependency on Underlying File System
Drawbacks and challenges of using Hive-style partitioning:
- Over Partitioning
- 물리적 그리고 논리적 partitioning 밀접하게 결합하면 over-partitioning을 유발
- 특히 카디널리티가 높은 파티션 컬럼 경우
year/month/day경우 그럴 수 있음 (** 카디날리티가 높다 = 고유한 값이 많다) - 이로 인해
지나치게 작은 파일, metadata overhaed 증가 그리고 수많은 파티션을 스캔해야 하기 때문에 query planning(쿼리계획)이 느려짐
- Cloud Effect
- Cloud data lake는
API 호출 제한으로 인해 over partitioning이슈를 악화시킴 - partition과 file 스캔 Job은 throttling을 만나 심각한 performance degradation(성능저하)으로 이어짐
- Cloud data lake는
- Poor Performance
- directory 기반의 partition의 query는 특정한 partition key를 지정하지 않으면, 느리다(특히 파티션 계층이 깊을떄)
하이브 테이블이 20개의 주로 분할되고 year=/month=/day=/hour= 파티션으로 분할된다고 가정하자. 6년동 100만개이상의 파티션을 축적함 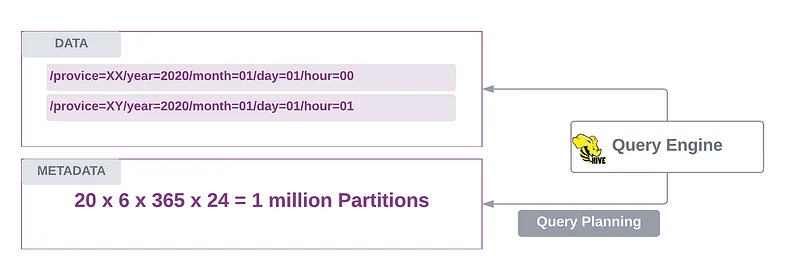
Drawbacks of using External Metastore
- 위의 단점 외에도 external metdata astore를 사용하는 Hive 스타일 테이블은 더 많은 challenge를 추가함
Thirft API를 통해 요청을 받아Metastore DB에 정보를 조회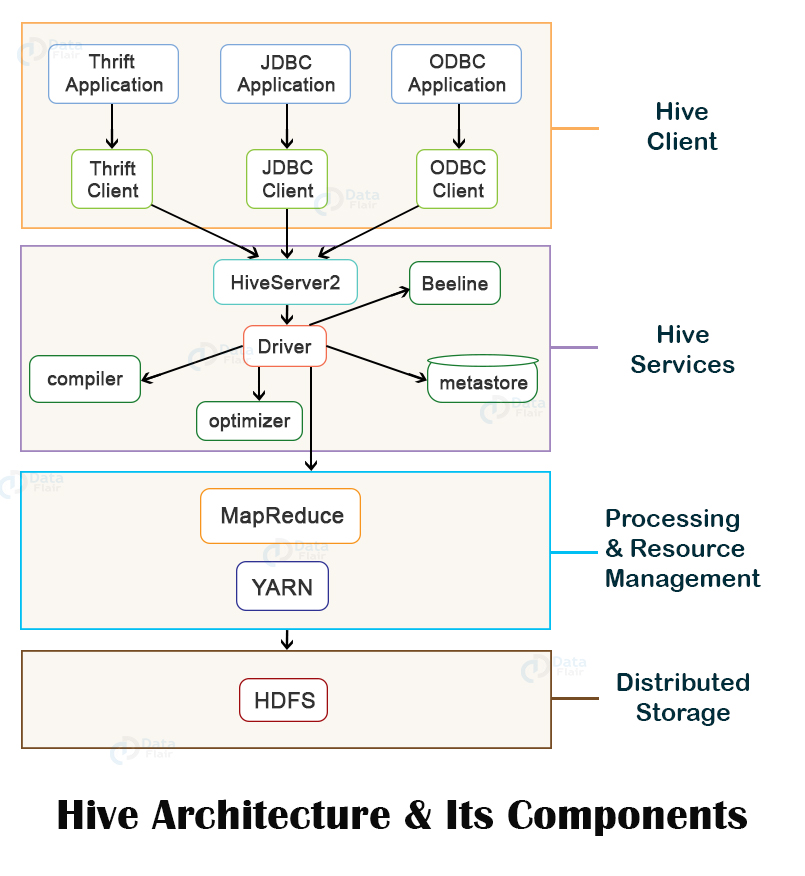
Thirft API? Apache Thifrt는 다양한 프로그래밍 언어간 통신을 가능하게 하는 RPC(Remote Procedure Call)프레임워크 클라이언트에서 서버 메서드 호출
- hive metastore architecture
- Performance Bottleneck(성능 병목 현상)
- Hive와 Impala는 모두 external metastore(일반적으로 MySQL이나 PostgreSQL와 같은 RDBMS에 생성)에 의존하는데 이는 테이블작업을 위한 번번한 communication으로 performance bottleneck야기 시킴
- Metadata Performance Scalability(메타데이터 성능 확장성)
- data volumne과 partition 증가로 인해, metastore가 점점 더 많은 부담을 가지게되고, query planning 느려지고 부하가 증가하며 잠재적으로 메모리 부족 오류(potential of out of memory)에러 발생
- Signle Point of Failure(단일 장애 지점)
- metastore는 단일 장애 지점을 나타냄. creash 또는 unavailability는 광범위한 쿼리 실패를 일으킴
- Inefficient Statistics Management(비효율적인 통계관리)
- partition level의 column 통계에 대한 hive의 의존성은 시간이 지남에 따라 성능을 저해 가능
- 수 많은 column과 partition이 있는 넓은 테이블은 방대한 양의 통계 데이터를 축적하여 query planning을 느리게 하고 DDL command에 영향을 준다
Transactional Guarantees on Data Lakes
차세대 Table format 논의 하기전, HDFS와 같은 분산파일 시스템이나 S3와 같은 object storage로 지원되는 datalake에 database 관리 시스템을 구현하는데 따르는 몇 가지 일반적인 과제를 살펴보자
Hive나 다른 데이터 관리 도구에 국한되지 않고, 일반적으로 기존 DBMS시스템의 ACID 및 transaction 속성과 관련
- Lack of Atomicity(원자성 부족) : 트랜잭션 내에서 여러 객체를 동시에 작성하는 기능은 기본적으로 지원되지 않아 데이터무결성(data integrity)에 방해
- Concurrency Control Challenges(동시성 제어) : 동일한 디렉터리나 파티션 내의 파일을 동시에 수정하면 트랜잭션 조정이 이루어지지 않아 데이터 손실이나 손상이 발생
- Absence of Transactional Features(트랜잭션 기능의 부재) : HDFS나 object storage에 구축된 Datalake는 기본 제공 트랜잭션 격리 및 동시성 제어가 부족. 트랜잭션 격리가 없으면 독자는 동시쓰기로 인해 불완전하거나 손상된 데이터를 접함
- Support for Record-Level Mutations : 스토리지 시스템의 불변성(The immutable nature of underyling storage systems)으로 인해 데이터 파일의 레코드 수준에서 직접 업데이트나 삭제는 불가능
Hive Transactional Tables
Hive ACID특징은 변경 불가능한(realm of immutable data lakes)에 구조화된 저장 보장, 특히 ACID 트랜잭션(원자성(Atomicity), 일관성(Consistency),격리성(Isolation),내구성(Durability) 도입하려는 최초의 시도
Hive Version 3(2016)에서 출시된 이 기능은 파티션 간 원자성 및 격리성과 같은 더 강력한 일관성 보장을 제공함으로써 큰 진전을 이룸
하지만 Hive에 ACId를 추가해도 근본적인 문제는 해결되지 않았는데, 그 이유는 아래와 같음
Hive ACID테이블은 디렉터리 중심 접근 방식을 기반으로하며, 기본 데이터 레이크 스토리지 계층 내에서 테이블 수준 정보를 관리하기 위해 별도의 메타데이터 저장소에 의존합니다.
Hortonwork와 Cloudera같은 공급업체는 Hive ACID를 더 광범위한 데이터 생테계 통합하기 위해 여러가지 시도 하였지만, 기본 설계상의 한계로 폭넓은 채택을 받지 못함
2nd Generation OTF — The Rise of Log-oriented Table Format(로그 지향 테이블 형식의 부상)
이전 세대의 테이블 포맷에서 주요한 이슈를 다시 나열 해보면
- 물리적인 파티션이과 논리적인 파티션의 긴밀한 결합
- 스키마 진화 및 데이터 변경 유연성 저하 (성능 최적화 및 유연성 저하)
- 디렉터리 구조가 파티션을 강하게 결정하므로 테이블 스캔시 전체 디렉터리를 탐색해야하는 문제
- 새로운 데이터 구조 필요할때 기존 데이터 이동 및 재분배 비용이 높아짐
- 파일 관리 어려움 (작은 파일 다수 생성)
- 운영 복자성 증가(확장성과 유지보수가 어려움)
- query planning 단계에서 파일 및 디렉터리를 나열하기 위해 파일시스템이나 개체저장소 API에 크게 의존
- schema,partition 그리고 column-level statistics(통계정보)를 유지 관리하기 위해 external metadata store를 사용
- record-level의 upsert,merge 그리고 delete에 대한 지원이 부족
- ACID와 트랜잭션 속성이 부족
위의 4,5 제외 1-3 문제에 대해 집중하면 파티션 및 파일 목록에대한 메타데이터를 효율적으로 저장할 수 있는 데이터 구조가 필요 이 구조는 빠르고, 확장가능하며 외부 시스템에대한 종속성이 없는 자체 포함형이어야함 (fast,scalable, and self-contained, with no depedencies on external systems)
LinkedIN의 Jay Kreps와 엔지니어링팀이 간단한 storage abstraction(시간순으로 정렬된 이벤트의 순차적 레코드를 포함하는immutable log)를 기반으로 Apach Kafka를 구축한 것처럼 비슷한 프레임워크 고려할 수 있을까?
immutable log가 Apache Kafka와 같은 시스템에서 항상 참인 사실을 나타내는 이벤트를 저장할 수 있따면, 같은 원칙을 적용하여 테이블의 메타데이터 상태를 관리할 수 있지 않을까?
log파일을 활용하여 모든 metadata 수정을 순차적으로 정렬된 event로 다룰 수 있음. 이는 Event Sourcing 데이터 모델링 패러다임와 같음
파일과 파티션은 metadata layer이 log의 모든 상태 변경을 추적하는 기록의 단위가 됨. 이 설계에서 the metadata logs are the fisrt class citizens of metadata layer
Managing Metadata Updates
데이터레이크 시스템의 immutable natrue를 고려할떄, metadata log는 지속적으로 추가 될 수 없음 대신에, 데이터 조작 연산으로 각각의 update 결과는 새로운 메타데이터 파일 생성을 필요로함
순서를 유지하고 테이블 상태 재구성을 용이하게 하기 위해 이러한 메타데이터 로그를 순차적으로 명명하고 기본 메타데이터 디렉터리 내에 구성 가능
query engine은 테이블의 현재 스냅샷 뷰를 다시 작성하기 위해 모든 메타데이터 상태 변경 이벤트를 재생하기 위해 이벤트 로그를 순차적으로 스캔 가능
Log Compation
대귬 데이터세트에 대한 빈번한 데이터 업데이트는 각 변경사항에 대해 새로운 로그 항목이 필요하므로 메타데이터 로그 파일이 급증 할 수 있음 시간이 지남에 따라 상태 재구성 중에 이러한 파일을 나열하고 처리하는 ovehead는 성능 병목현상이 될 수 있음 이는 메타데이터 관리 분리의 이점을 없애는 현상
이를 완하하기위해
- 주기적으로 압축 프로세스(periodic compaction process)는 개별로그의 파일을 통합된 파일로 병합
- time travel 그리고 rollback의 경우 이러한 오래된 이벤트는 지정된 기간 동안 보관해야함
What did we just build?
데이터 파일과 함계 테이블 메타데이터를 관리하기 위해 간단하고 변경 불가능한 로그(simple, imuutable trasactional log)를 사용하여 초기 요구사항을 해결하는 테이블 형식을 만듬 이 접근은 bedrock for modern open table format(open table format의 근간)이 된다 Apache Hudi, Delta Lake 그리고 Apache Iceberg
The modern open table formats provide a mutable table layer on top of immutable data files through a log-based metadata layer. This design offers database-like features such as ACID compliance, upserts, table versioning, and auditing.
modern open table format은 log-based metadata layer를 통해 immutable data file위에 mutable table layer를 제공
- 이 디자인은 ACID compliance,upsert,table versioning 그리고 audting을 제공
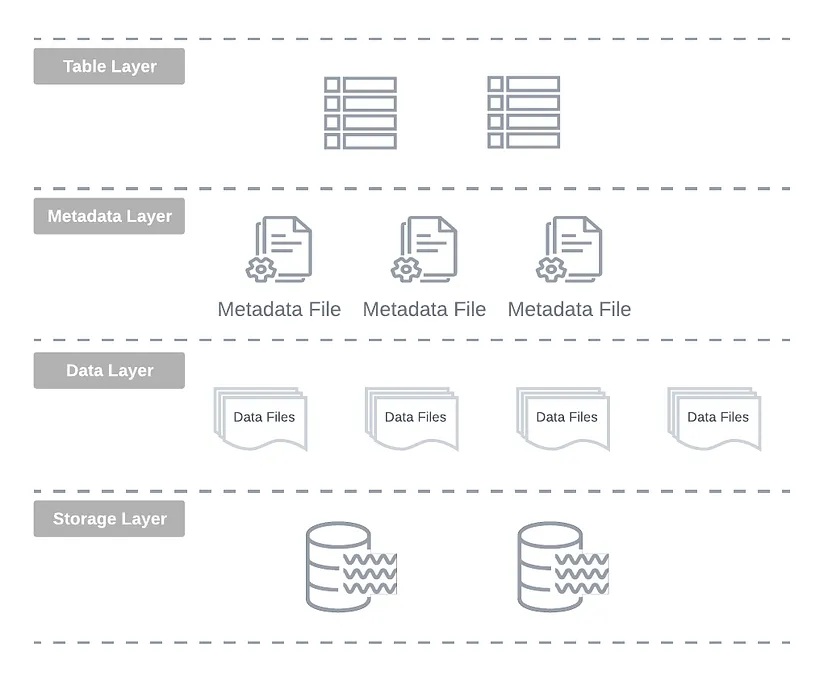
The Origin of Modern Open Table Formats implementations
현재 세대의 open table format은 이전 세대의 data lake의 data management접근의 한계를 해결하기 위해 탄생. 그리고 이 tool들의 근간은 log-structured metadata organisation에 존재
- Apache Hudi
- Ubery in 2016에서 시작
- 주로 HDFS에서 ACID보장을 제공하는 동시에 확장 가능하고 Upsert와 data lake streaming 수집을 가능하게 하는것을 목표
- 그것의 디자인은 mutable data streams을 최적화하는데 초점
- Apache Iceberg
- Netflix 2017에서 출시. Hive의 schema 중심 (directory-orientied table format)의 확장성과 트랜잭션 제한에 대한 대응으로 개발
- Delta Lake
- 2017년 Databricks에서 소개되고 2019년에 오픈소스화됨
- 주요 목표는 ACID transaction기능을 cloud storage object기반 데이터레이크 위에 제장
Industry Adoption
- 지난 몇년동안 차세대 open table format이 다양한 데이터 도구와 플랫폼에서 널리 채택되고 통합 되는 추세
- 주로 이러한 제품을 관리형 서비스로 제공하는 Saas공급업체사이에서 시장 지배력을 놓고 치열한 경쟁이 이루어짐
- Microsoft : 최신 Onelake 및 MS Fabric 분석 플랫폼에 Delta lake적용
- Google : BigLake플랫폼의 기본 테이블 형식으로 Iceberg를 채택
- Cloudera : Apache Iceberg를 중심으로 오픈데이터레이크 하우스 솔루션을 추구
- OSS : Presto,Trino,Flink 그리고 Spark도 현재는 open table format Readmin/Writing을 지원
- 주요 MPP 그리고 cloud data warehouse vendors(Snowflake,BigQuery그리고 RedShift) : 외부 테이블 기능을 통해 자원을 토앟ㅂ
3rd Generation OTF — Unified Open Table Format
- open table format 발전은 새로운 추세
cross table interoperability로 발전하는 추세 - 이 개발의 목표는 기존의 모든 주요 포맷과 원활하게 작동하는 통일되고 보편적인 오픈 테이블 포맷 만드는것
- 현재 포맷 간 변화에는 메타데이터 변환과 데이터 파일 복사가 필요. 그러나 이러한 포맷은 기반을 공유하고 종종 parquet을 기본 직렬화 포맷으로 사용하기 때문에 상호 운용성에 상당한기회가 존재하지
- uniform metadata layer는 모든 주요 오픈테이블 형식에서 데이터를 읽고 쓰는데 통합된 접근방식을 약속
The State of Art
- **OpenHouse 2022년 소개
- Linkein에서 개발
- Apache Iceberg위에 구축됨. Spark와 완벽하게 통합하여 RESTful Table Service를 통해 기본 형식에 관계없이 테이블과 상호작용하기 위한 인터페이스 제공
- **Apache Xtable(OneTable)
- Onehouse에서 2023년 도입
- 스키마, 파티셔닝 세부정보 및 열 통계에대한 공통모델을 사용하여 지원되는 모든 형식에대한 메타데이터 생성하기 위한 가벼운 추상화계층 제공
- **Delta Uniform
- Databrcks에서 2023년 도입
- 자동으로 Delta Lake 및 Iceberg 테이블에대한 메타데이터를 생성.
- 공유 parquet 데이터 파일의 단일사본을 유지
- 외부 애플리케이션과 쿼리엔진이 다른 형식을 읽을 수 있도록 하는 동시에 Delta Lake를 기본형식으로 사용하는데 중점
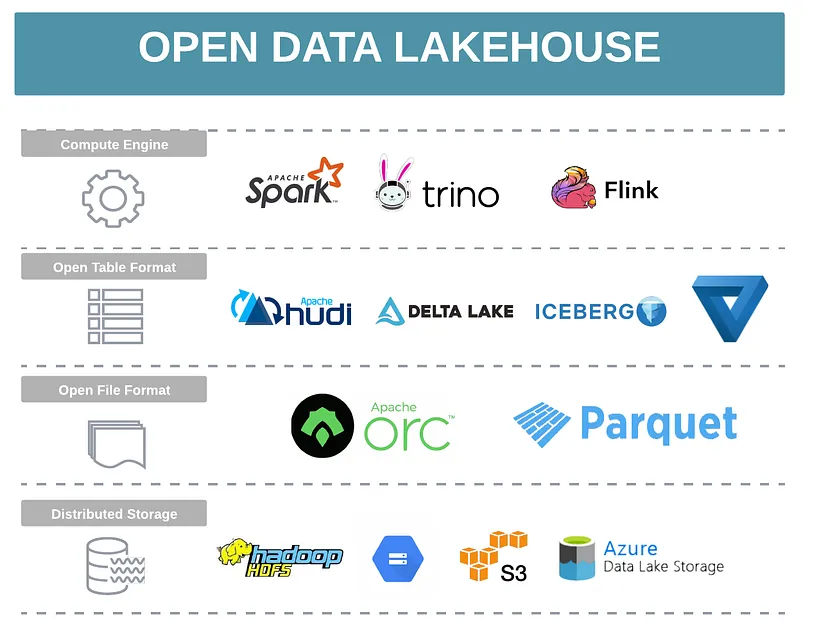
Data Lakehouse
- 정의 : 데이터레이크 비용 효율성, 확장성, 유연성 및 개방성과 일반적으로 데이터 웨어하우스의 관련된 성능, 거래보장, 거버넌스 기능을 결합한 통합된 차세대 데이터 아키텍처
- 정의는 open table format과 매우 유사. open table format을 사용하여 ACID,감사,버전 관리, 인덱싱을 저가 클라우드 스토리지에 직접 구현하여 이 두가지 데이터 관리 패러다임간의 격차를 메우는데 기반
- 조직이 데이터 레이크 스토리지를 기존 데이터 웨어하우스처럼 처리할 수 있도록 해주고, 그 반대 경우도
- 원래 Hadoop플랫폼에 데이터 웨어 하우징을 제공하기 위해 SQL-on-Hadoop도구를 통해 추구 되었지만, 데이터 환경이 발전하면서 최근에야 완전히 실현
Non-Open vs Open Data Lakehouse
- 일반적으로 data lakehouse와 open data lakehouse를 구별하는것이 중요
- AWS와 Google과 같은 CSP는 자사의 dataware house 중심 플랫폼을 data lake house라고 부르지만 실제로 그들이 정의하는바는 더 크다
- 그들이 강조점은
- 반구조화된 데이터를 저장
- Spark와 같은 외부 workload를 지원하고
- ML모델 교육을 가능하게 하고
- open data file을 쿼리하는 데이터웨어 하우스 기능
- 위의 강조점은 모두 데이터 레이크와 관련된 특성
- 일반적으로 storage와 compute 아키텍처 분리가 특징
- open data lakehouse
- low-cost data lake 스토리지위에 있는 데이터를 관리하기 위해 주로 오픈 테이블 형식을 활용
- 이 아키텍처는 더 높은 상호 운용성과 유연성을 제공하여 조직이 각 작업이나 워크로드에 맞게 최적의 컴퓨팅 및 처리 엔진을 선택할 수 있도록 합니다.
- 오픈 데이터 레이크하우스는 시스템 간에 데이터를 복제하고 이동할 필요성을 없앰으로써 모든 데이터가 원래의 개방형 형식으로 유지되도록 보장하여 단일 진실 소스 역할을 합니다 .
- Databricks, Microsoft OneLake, OneHOuse,Dremio,Cloudera 클라우드에서 관리되는 open data lakehouse 공급업체