(2)Apache Spark Interview
1.What is DAG in Spakr, and what is its purpose?
DAG(Directed Acyclie Graph)은 각 stage가 병렬로 실행될 수 있는task의 집합으로 이루어진 일련의computation stageDAG Scheduler는job을shuffle경계를 기반으로job을stages of task로 나누고 이러한stage들을 올바른 순서로 실행하여 최종겨로가를 계산하는 역할을 함DAG의 목적은performance와fault-tolernace을 위해execution plan을 최적화하는것
2. if data can be spilled to disk, why do we encounter OOM erros?
- executor memory limit : intermediate RDD 메모리에 맞지 않은정도로 큰 경우
- memory leaks : inefficient code난 bug때문
- improperly tuned memory settings : executor나 driver에 메모리가 부족한 경우
- skewed data : 특정 partition이 다른 partition보다 상당히 커서 메모리 사용이 고르지 않은경우
- complex transformation : 대량의 중간데이터를 메모리에 동시엥 보관
3. How does Spark work internally?
Job Submission: The user submits a Spark job via a SparkContext.
DAG Creation: The SparkContext creates a logical plan in the form of a DAG.
Job Scheduling: The DAG scheduler splits the job into stages based on shuffle boundaries.
Task Assignment: The stages are further divided into tasks and assigned to executor nodes.
Task Execution: Executors run the tasks, processing data and storing intermediate results in memory or disk.
Shuffle Operations: Data is shuffled between executors as required by operations like joins.
Result Collection: The final results are collected back to the driver node or written to storage.
4.What are the different phases of the SQL Engine?
The different phases of the SQL engine in Spark include:
Parsing: Converts the SQL query into an unresolved logical plan.
Analysis: Resolves the logical plan by determining the correct attributes and data types using the catalog.
Optimization: Optimizes the logical plan using Catalyst optimizers.
Physical Planning: Converts the optimized logical plan into a physical plan with specific execution strategies.
Execution: Executes the physical plan and returns the result.
5.Explain in detail the different types of transformations in Spark.
Transformations in Spark are of two types:
- Narrow Transformations: These transformations do not require shuffling of data across partitions and can be executed without data movement. Examples include:
– map(): Applies a function to each element.
– filter(): Selects elements that satisfy a condition.
– flatMap(): Similar to map but can return multiple elements for each input element.
- Wide Transformations: These transformations require shuffling of data across partitions and involve data movement. Examples include:
– reduceByKey(): Aggregates data across keys and requires shuffling.
– groupByKey(): Groups data by key, resulting in shuffling of data.
– join(): Joins two RDDs based on a key, involving shuffling.
6. Spark Jobs : Stage,Shuffle,Tasks,Slots
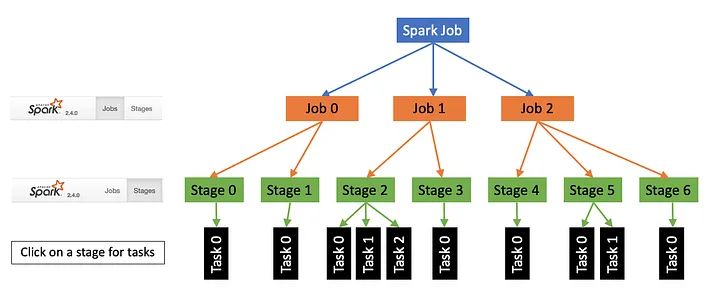
- Spark creates one job for each action.
- This job may contain a series of multiple transformations.
- The Spark engine will optimize those transformations and creates a logical plan for the job.
- Then spark will break the logical plan at the end of every wide dependency and create two or more stages.
- If you do not have a wide dependency, your plan will be a single-stage plan.
- But if you have N wide-dependencies, your plan should have N+1 stages.
- Data from one stage to another stage is shared using the shuffle/sort operation.
- Now each stage may be executed as one or more parallel tasks.
- The number of tasks in the stage is equal to the number of input partitions.
task는 Spark job을 위해 가장 중요한 concept이며 smallests unit of work in Spark job. Spark driver는 이 task들을 executor에 할당 그들에게 일하도록 요청